| Journal - Week 9 Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
|
For the beginning of this week all I have to do is run some tests. I've made sure to have lots of them running, because I'll be going on vacation for a week. I don't need to supervise the tests while they're running, so I'll have something to work with when I get back. I'm mostly testing what difference it makes to give a greater reward at the goal, and finishing off a few tests that have been lagging behind. *********VACATION********** Well, I'm back from vacation. I was gone about a week, with my boyfriend and his family, to Ste-Irenee and Alma, which are in the north of Quebec, about 5 hours away from Montreal. We went mountain-climbing (a good 5 hour treck), and took a cruise on the St-Laurent to see the whales (belugas, fin whales, seals, and more). Then we headed to Alma for my boyrfiend's karate camp, where he got up at 7AM every morning, and had two two-hour trainings per day. I also got up early, but didn't train... Instead I did a very difficult and grueling activity: reading in the grass, watching little rabbits hop by. On our way back we stop by a beach and built a tiny village out of flat rocks, wood, feathers and plants. All in all, it was an awesome trip. Lots of fun, and I came back with a beluga teddy and a Japanese calligraphy brush, from one of the senseis. YAY! *********BACK TO WORK********* Amazingly, some tests were actually not finished by the time I got back. But, it did show me something: the tests with lambda=0.6 do work.... It just takes about 10 days per trial, a ridiculous amount of time, and doesn't learn anything new. Apart from that, I can see the difference the end reward makes. I think this is a very important point. In general, I supposed that this is something you can set yourself in your agent, how much to reward it when it accomplishes something. It is really very important to set a high enough goal, otherwise it gets, "depressed", I guess, and doesn't learn because everything is bad anyway. The agents with the higher goal-rewards did not always have a clear idea of the optimal path (they all start off going the safe way, but partway through they think to loop - it's a good thing we keep exploring!), but they showed much better results, most of the time getting a positive reward. Here is a comparison between goal-rewards of 500, 1500, 2000 and 2500 for a temperature T=15. For the plots of the agents with the higher goal-reward, I subtracted an amount from each episode, so that the extra reward (in these cases, 1000, 1500 and 2000) aren't included; so, the graph shows how much better the agent is doing. 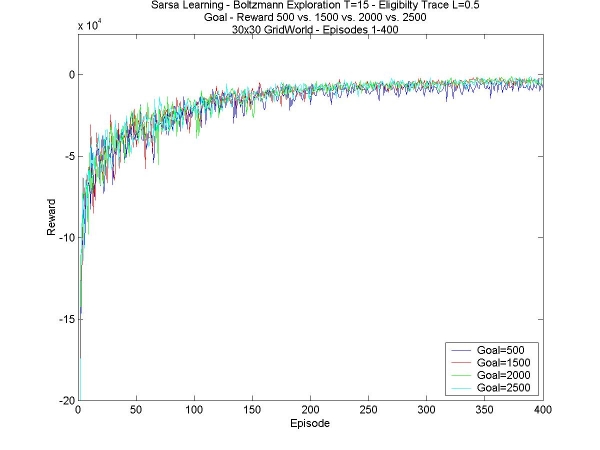
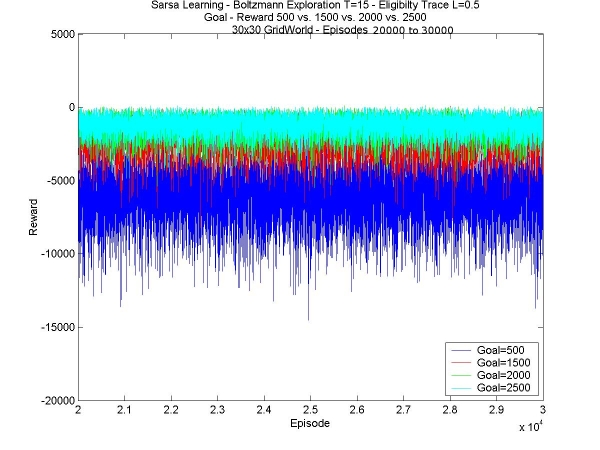
We can see that the higher the goal-reward, the better the agent performs, but that there is very little difference between the goal-rewards of 2000 and 2500, except that the rewards vary a bit less. It seems that the performance reaches a plateau, and increasing the goal-reward indefinately won't improve anything. This looks like a trend for any technique used, and that each of these techniques' parameters has to be set just right for maximum performance (like the lambda value for eligibility traces: if it's too high, it stops working completely). I'm also waiting for tests to finish with different goal-rewards for different values of T. I want to see whether the temperature changes anything to the optimal goal. I also am trying out an even higher goal value, to see if does tend to stabilize the agent, like we can see between the two highest goal-rewards above. We'll see next week what it gives. |
||||||||||
|
Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||