| Journal - Week 3 Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
|
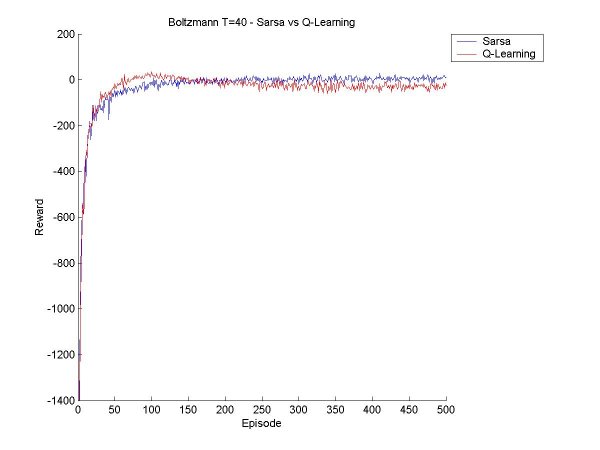
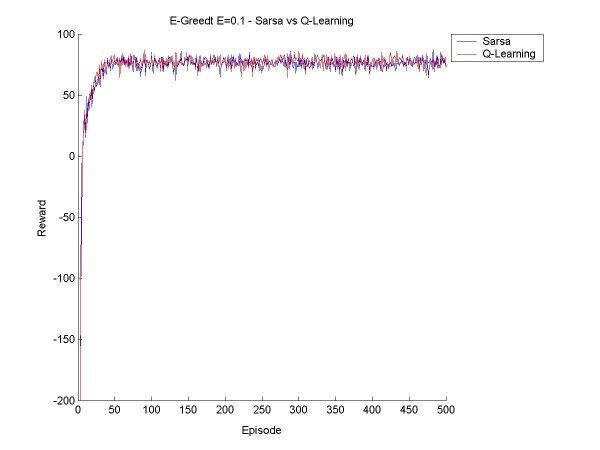
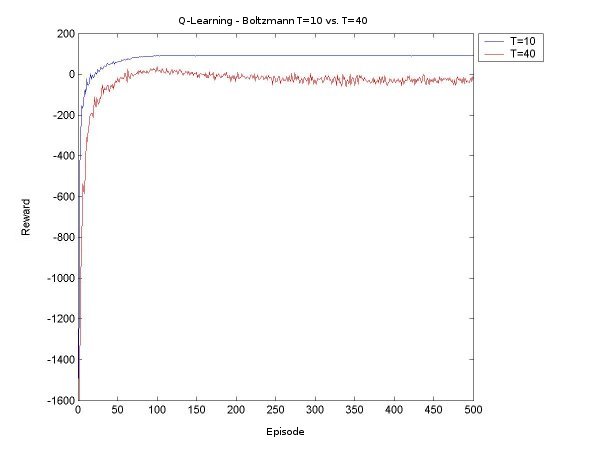
The idea this week will be to get Sarsa and Q-Learning agents that select moves according to Boltzmann selection, and find a few values for the temperature constant so that we get a good range of possible behaviour. Then we can compare the Sarsa and Q-Learning agents with Boltzmann and Epsilon Greedy, with various values for epsilon and the temperature. First things first. Since the agents will need to learn over many episodes, it may take a good long time to train the agent, and if something crashes halfway through, a lot of data is lost. So I have now implemented save and retrieve functions for the Q-values. I also made a few other additions to the code, mostly saving various results to disk rather than just print them to screen, and making it possible to seed the random number generator (for probabilities). I also tried to make a main function that took input from standard input, but it turns out that I've only done this in C before, and searched high and low for a way to read an int (just an int, that's all!), but it seems it's rather complicated in Java. I gave up on this since it is not really essential. Now for the real work. After a little bit of coding and a little bit of reorganization, I created a surprisingly bug-free Boltzmann move selector for Sarsa and Q agents. I started off testing it for a Sarsa Learning agent. As a general rule, as T (temperature) increases, the agent learns to take a 'safer' path around the cliff. When the values for T get too high, the agent can't seem to stick to its path though, there's too much exploration, but it does believe in a good path (that is, if it selected greedily, it would find a good path). Something I found particularly interesting is that at the beginning of its learning session, in the first 100 episodes or so, it believes the 'dangerous' path is optimal, but as it goes on it panics and even takes the furthest path possible. For example, at T=40, after 200 episodes, the agent thinks the dangerous path is optimal ~60% of the time, and takes a path one square away ~32% of the time. But after 400 episodse, it prefers the path two squares away (33%) and one square away (31%). I finished the first tests, and made a few graphs to show the results and compare the various methods. All the results below are averages from 100 runs of agents learning over 500 episodes. 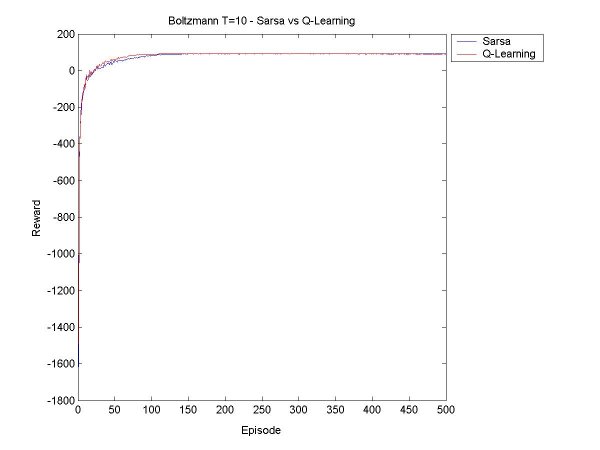
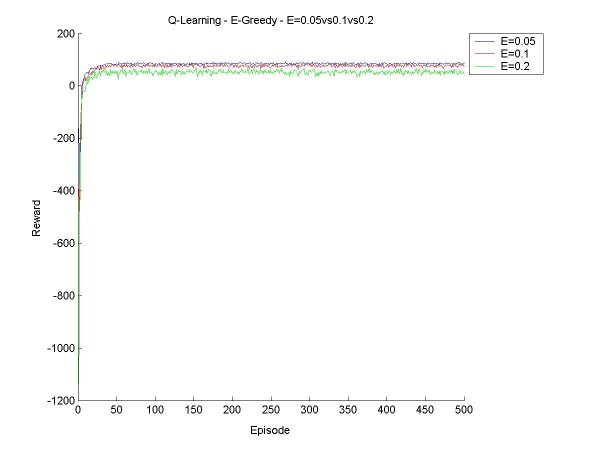
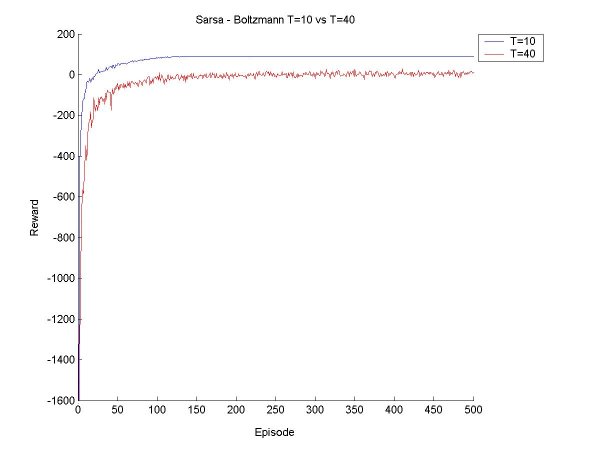
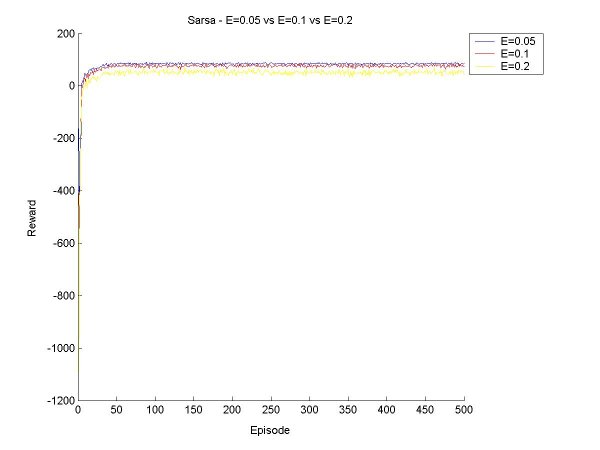
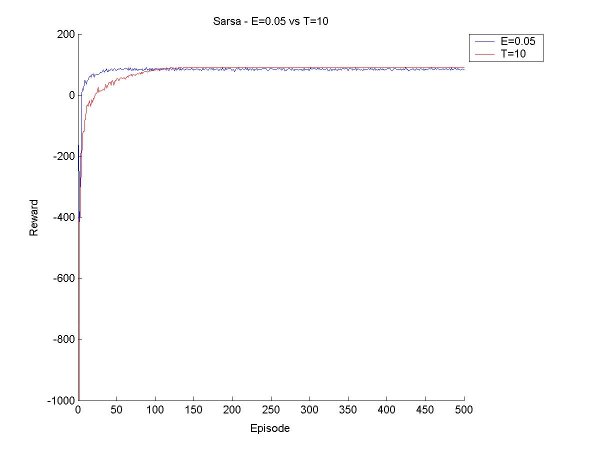
|
||||||||||
|
Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||