| Journal - Week 6 Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
|
This week I will not be coding anything new. Instead, I have to run a lot of tests. Long tests: a single test on the 30x30 world can take a whole week to finish. I'll be testing on several computer in the machine learning lab, trying to see what difference the eligibilty traces make, as well as what difference the temperature makes. The configuration I have come up with for the 30x30 world doesn't test the same thing as the smaller world. Instead, I have only one goal, to which there is a short, dangerous (cliff-lined) path, as well as a long, safe route. The configuration is represented in the image below, with cliffs in orange, obstacles in blue-gray, and the goal in gold. 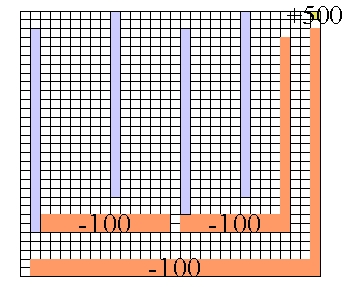
The results are coming in very slowly. So far, it seems 35000 episodes is not enough: an agent with T=10 (L=0.1) usually will not know the optimal path by this time. T=20 (L=0.1) seems to have better results aven after only 10000 episodes. Looking more closely at the paths the agent was learning, I realized that it was taking a path apparently through some obstacles. The world was not properly defined, and gave a completely un-interesting world. So I had to throw away about 4-5 days worth of testing. I corrected my mistake, and now the world corresponds to the world I described in week 5. I'm running my tests on the Machine Learning lab computers and they should be done by next week. In the meantime I'm working on a better design for my website (not that plain text is not beautiful... who wouldn't love the most boring website ever??), and writing my Progress Report. This week I also continued running some tests on the smaller, 24x15 world (see week 4 for configuration). What I really wanted to see was how the agent performed after a longer learning period. The tests I ran are the same as last weeks', but with 25000 episodes rather than 10000. I was hoping to see that the agent eventually learned to always find the better goal, but it seems that for these parameters, it can only find it about half the time. Click on the graphs to see a larger version. 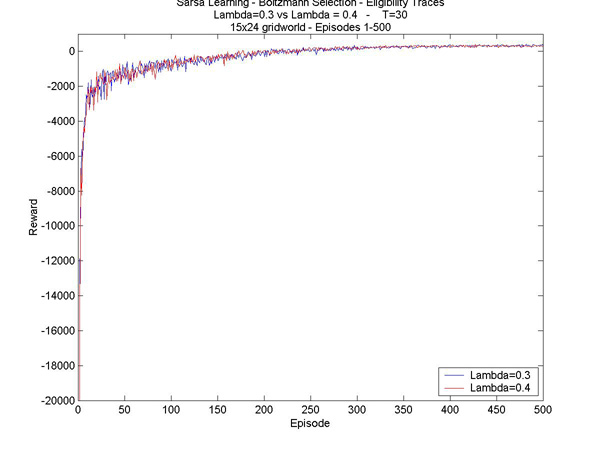
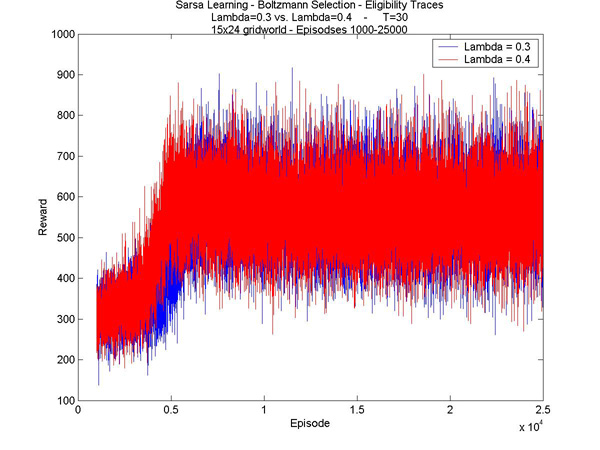
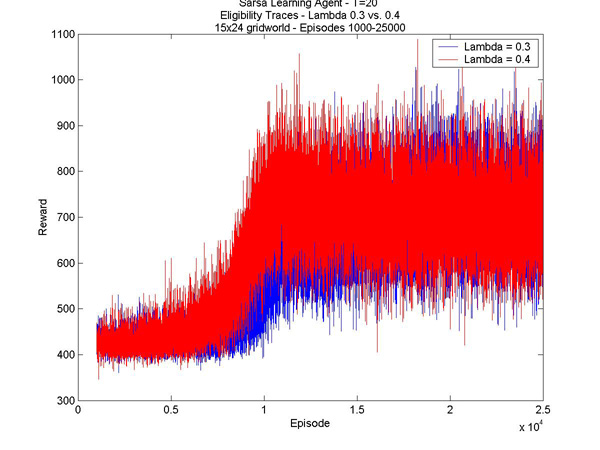
The last thing I did this week was make a comparison between the normal learning rate and increased learning rate (recall, this is a technique in which the agent learns faster in disaster situations). In all the test I was using the increased learning rate, but I wanted to take a moment to see what difference it makes on a larger scale. Here's what I found: 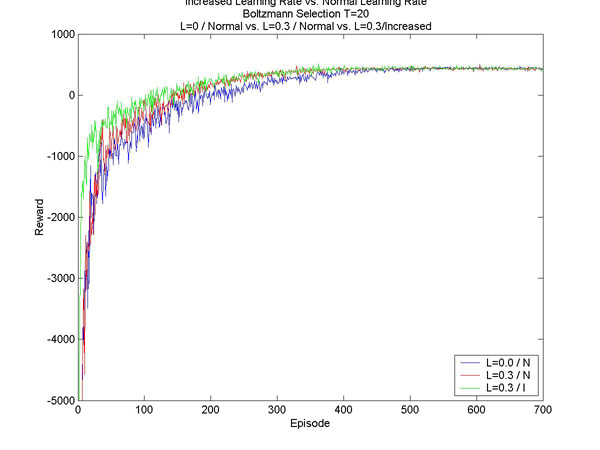
Here I am comparing between the speed of learning with eligibility traces as well. We can see the advantage of both quite easily: the higher value for lambda (in red) shows a slight improvement even in the beginning; the increased learning rate (shown in green) shows a drastic improvement in the first few trials. The increased learning rate is particularly nice, in that it doesn't slow down the computing time at all, unlike the eligibility traces. |
||||||||||
|
Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||