| Journal - Week 10 Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
|
Well, this is it, the last week of work. I don't have time to start anything new, but I do have to time to wrap up all that I wanted to test. This includes comparing various values of temperature, with the same goal reward and value for lambda, as well as various values for lambda with the same temperature and goal reward, and finally seeing whether a higher reward really does tends to stabilize the total reward the agent manages to collect. First of all, different temperatures: I compared T=10, T=15 and T=20. In all other respects the agents were the same, with lambda=0.5, fast disaster learning, and the goal reward was +2500. The trend is that smaller temperatures are better. They learn faster in the beginning and have much higher values in the 1st episodes (see 1st graph below), they have a higher maximum total reward obtained (see 2nd graph below), and less variance (see 3rd graph below). 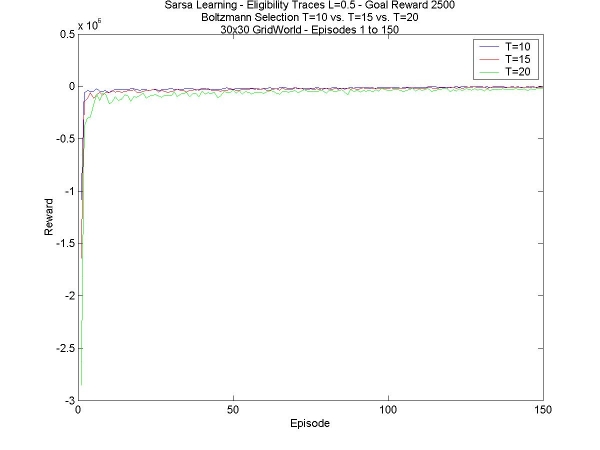
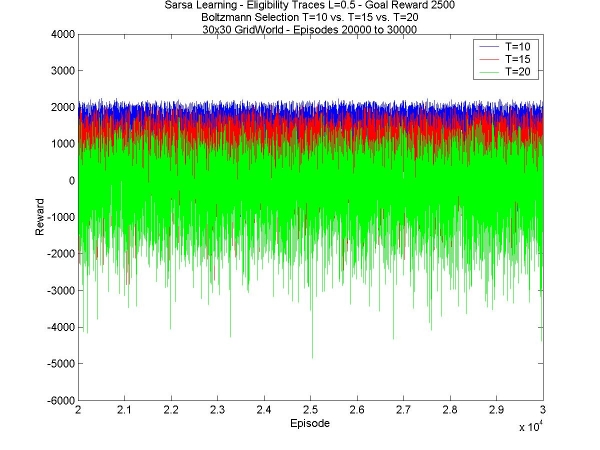
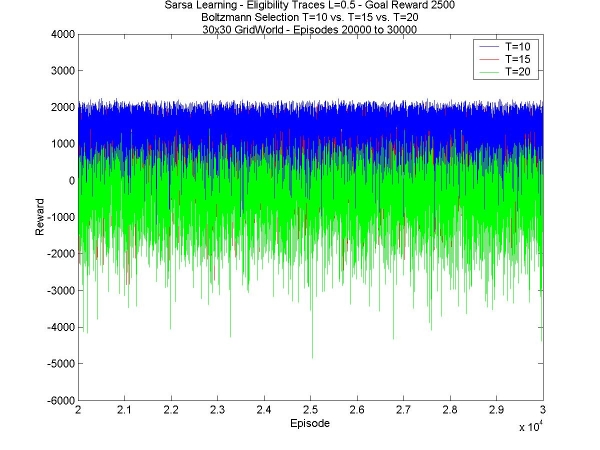
This is pretty much the results that were expected. In the 24x15 world, the same happened, but the higher temperature managed to find a hidden goal that the lower ones couldn't find, and eventually the reward was greater (see week 4). The bigger world has no hidden goal, so there's no advantage in the higher temperature. Secondly, different values of lambda. I've compared L=0.1, L=0.3 and L=0.5. Once again, the agents are the same in all other respects; in this case, the temperature was 15, and the goal reward was +3500. The results are got weren't very inspiring. There was hardly any difference at all between the three values. The only difference I can see is that higher values of lambda (0.6, for instance) don't work at all. This is strange behaviour considering how little difference there seems to be. 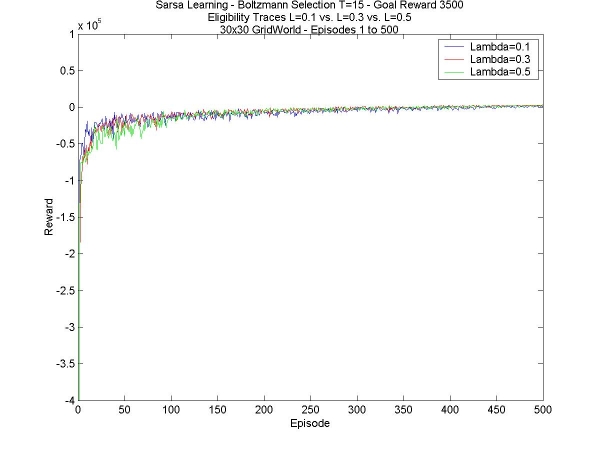
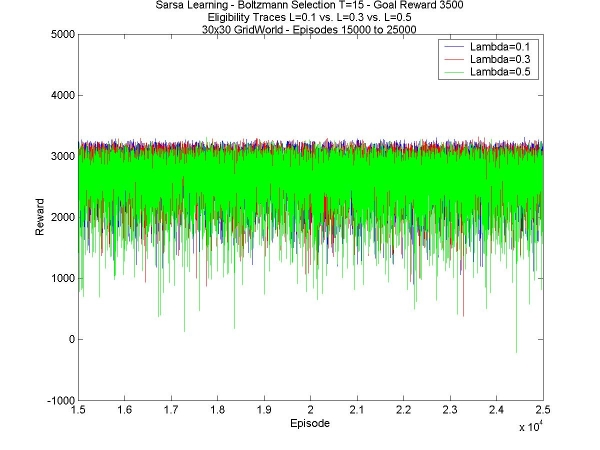
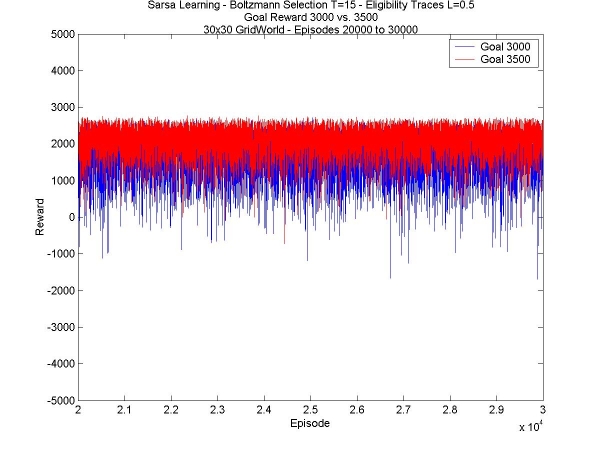
The results, though not spectacular, were also expected. In the smaller world, eligibility traces made no difference at all in stabilizing the final reward, or increasing it. They helped find the second goal faster, or just helped find it when the agent did not explore enough to find it on its own (see week 5). Lastly, I have another comparison between different values for the goal reward. As I noticed last week, the higher the reward, the more stable the final reward collected by the agent. It doesn't really increase the total reward, but the extra stability is nice, giving a higher average. The reason for this is most likely that having the higher reward increases the probability of taking the path to the goal; this is obviously an advantage in the 30x30 world, but it reduces exploration, which, as we saw in the 24x15 world, is critical for finding hidden goals. 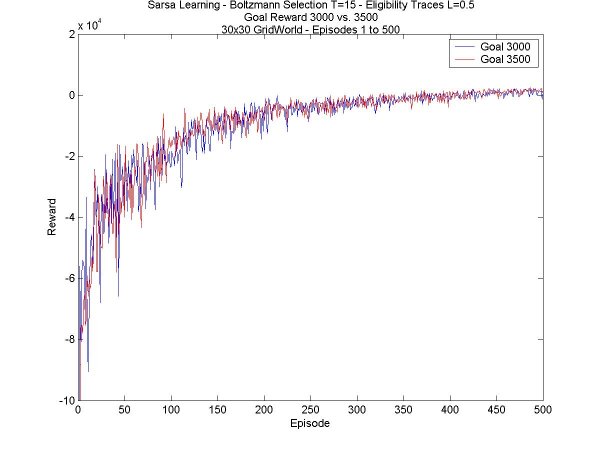
Well, that is the essence of my findings over the whole summer of work. I learned a lot about reinforcement learning, and it was all very interesting. I used some neat techniques that sometimes really helped the agent out. All in all, I think the results were interesting, but that something isn't quite right about it all. The fact is, it really depends a lot on the world the agent is working in. In the larger world, lower temperatures were much better, no question, but it was the opposite in the smaller world, on which there was an optimal temperature, neither too high nor too low. The use of eligibility traces didn't have this kind of problem. It was useless but not problematic in the larger world. However, the use eligibility trace slows down considerably the computing time, which will be a problem as the environment gets larger and larger. My conclusion is that, while this is all very useful in small, slightly controlled cases, in a large, completely unknown environment, there is just too much fine-tuning to do on all the parameters. Most likely real progress will be done in another direction; probably clustering states together will be something to look at next. |
||||||||||
|
Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
{kind=link}
{kind=link}