Problem Description and Importance:
Distributed systems, such as the Internet, have been formed upon either the asynchronous model or the synchronous model. The asynchronous model is defined with very few assumptions about timing and processing information. Although the asynchronous model has been validated, it is not a practical model that can be used in all scenarios. Furthermore, it is impossible to make a distinction of a process that is running slowly or if it is actually a failed process. The synchronous model includes strong assumptions about processing speeds, delivery delays and clock information. These strong assumptions are hard to hold to on distributed systems away from the research labs. A more practical model that can be defined is the partial synchrony model which is model that falls in between the asynchronous and synchronous models. The partial synchrony model is based upon assumptions that deal with local clocks and include drift rates.
The importance of this problem is to be able to create a valid and practical partially synchrony model for the internet. As research is conducted and data is collected, new algorithms will be formulated that have previously been impossible for the asynchronous model and not realizable for the synchronous model.
Activities and Results:
This summer started out with learning how about the current protocols in the internet, TCP and UDP. This helped me learn about how the internet currently works at levels lower then the application. I was able to see and observe the difference between clients and servers, and how TCP and UDP are different from each other.
Once I had a good grasp on these two protocols, and had written and modified clients and servers from a text book, Unix Systems Programming by Robbins, I was to deploy my client and server to PlanetLab. PlanetLab turned out to be quite an adventure. Deploying the client and server ended up to be more work then was initially thought, and so it was decided to forgo the deployment and start the preliminary work to conduct some timing experiments. The beginning adventure in doing the experiments was to use fping, a program which I was successfully able to install on my local machine. Fping was created to run similarly to ping, but with various options to be able to ping multiple machines in a single command. I then started to create a script which would use the fping program and collect the data into a single file which I could then parse through at a later time. This was working wonderfully until it came time to install fping on PlanetLab, and so the efforts to use fping were then pushed to the side, and the Scriptroute service was then investigated.
Scriptroute proved to be the answer to all our problems. I was able to take a ruby script that they had already written, and modified it so that it would ping multiple hosts ten times when the script was running, performing the same functionality as fping did. The one downside to scriptroute is that it would only run for a timeframe of about 100 seconds. To be able to collect data that is of any use, I needed to be able to collect data over long periods of time. So to solve this problem, I ran my script initially through a proxy which then gave me the data the web interface of scriptroute was sending to its server. I then took the post method and created a perl script which would send the script to the scriptroute server. The perl script would send the script, wait for 60 seconds and repeat, until a count of 120 was reached. This allowed for data to be collected over a period of about two and a half hours. I also included another sleep cycle in the perl script which lasted for a period of either four or six hours (depending on which script was run), and then the first part of the script which was when the data was collected was run again. These scripts were run to give me data to ten different servers from a single scriptroute server.
When I was able to sit down to analyze the data, I found that some of the servers were more stable then I would have initially thought. One example of this is a server that was located in Athens.
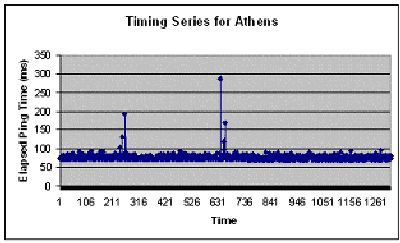
This graph shows periods of stability for the most of the time frame that this data was collected in, with a few exceptions when the message latency was much longer then the average time around 75 ms.
However, there were some servers that were more abnormal in their behavior, such as a server located in California.
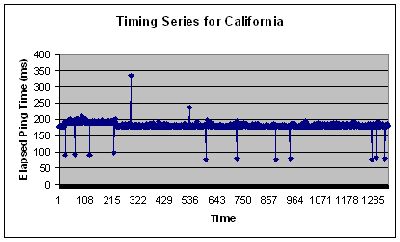
This graph shows that although there is a good portion of time which the server was stable, there are some portions which the request took much longer then normal, and even some that got back much sooner! The longer responses are easier to understand if the server had a heavier work load at that time, and trying to process all the requests it was receiving. However, the faster responses have leads to the conclusion the lower bound is not quite as trivial as was once thought. The reasoning for this is still yet to be determined.
Future Work:
The initial research that I have done this summer will eventually lead the evaluation and validation of the partial synchrony model. This will lead to publishing the results about this model. Additionally, a PhD student will use the results as a preliminary step to his doctoral thesis about the partial synchrony model.