


Amrita Mazumdar
DREU 2013 @ Brown University
Published 03 Jul 2013
Week Four Accomplishments:
- Optimized and fixed fault simulation scripts
- Reorganized some file generation folders
- Got my email address!
Week Five TODO:
- Add some more automation to the fault simulation
- Run SPICE simulations on my latched rd53 circuit and the different versions of the rd53 circuit from the implication insertion
Day 5 (7/5)
- Today I worked out the differences between fault_analysis and fault_two, which has been a big mystery to me for a while. I also figured out the purpose of the recursive io_list method in the atpg-sim, which had been perplexing me for a few days as well.
- Turns out there are some subtly different methods in fault_two than in fault_analysis, and that there are some extra lines in each method that result in some more different work being done. I have yet to see why there are certain methods being re-run on the files in fault_two, but I'm sure if I just more carefully go through each file change I can parse it out.
- Also, I got my e-mail address! (finally) so I sent a request for access to the oscar server and hopefully when I get it I can begin spice sims!
Day 4 (7/4)
- Today was a holiday but I put a little work in because I wasn't sure how much I could do tomorrow (taking my computer in for another checkup, things actually seem fine but wanted to see if I could convince the Apple store to fix my logic board so I don't have to walk around with this external mouse all the time "just in case").
- I spent my work time today doing triage on the atpg-sim folder, figuring out where the file creation happens and where everything gets store and cleaning up a lot of unnecessary code and file generation. I left a lot of the create_vectors code commented out because it might be useful when I do modifications to the fault simulations, because it has all the right formatting for strings and will prevent silly mistakes later. Most of the code there is just file parsing, which I take no issue with. There is some recursive method that I don't entirely understand, but should try and understand because it takes one list of patterns and somehow generates another, more simplified one?
Day 3 (7/3)
- Lots of good and semi-good news today: the fastscan license servers came back, so I was able to start work almost immediately upon returning. Also, I got an email saying my Brown email could be set up! But when I tried to get it working, something wasn't working in the sign-up page. Upon discussing with the engineering administrator, we determined my birthdate was stored incorreclty, and, while we were able to fix it, I'd have to wait for the system to update overnight before I could make an email address.
- Today I spent time cleaning up and fixing up the fault-sim and atpg-sim scripts. Specifically, each script had a lot of commented out areas and some ambiguous print statements left for things that weren't happening, and I just took the time to figure out what was going on in each script, clearning out everything unnecessary and old, and writing more detailed output messages and comments where I could. I also read through some fastscan documents and lectures I found online so I could really understand how the outputs were being parsed. I figure if I'm going to eventually add my own scripting to the fault simulations to synthesize some better circuits, I should work on understanding the outputs to ease my work later. So I did that, I now get what PFM means (pattern, force, measurement), it comes out of the fastscan simulations. I think my big TODO for next week (when I get my email) will be to simulate some outputs in Spice and maybe try to automate adding a fault-based implicant to a circuit and simulating that output. Probably adding the fault-based implicant automatically will be the hardest part, but I should start that part.
Day 2 (7/2)
- A good comparison for my current workflow is like slowly and carefully chipping away at an iceberg of code and data in hopes of one day carving it into a beautiful ice sculpture. Until then it's a big scary melting mess. I say melting because today, in the middle of all my testing and careful examining and simulations, the license servers went down (I think). All I know is my simulations stopped working because of a missing or invalid license, and I e-mailed the Brown administrator for these things with no response yet (to be fair, he probably had gone home). So that probably accounted for many of the perplexities I dealt with today, and I wouldn't have even caught it because all system output from the simulation program was piped to /dev/null.
- There are two folders where steps of fault simulation happen, fault-sim and atpg-sim. These folders have almost identical contents, aside from additions to some lines of some files and commented out lines in various different places in each set. The run-me.sh files do almost the same thing, just with slightly different parameters and names given to fastscan, and the readme files are both the same and totally irrelevant to the function of the files in the folder.
- So,
today I did some housecleaning, deleting and renaming and commenting each of them.
There's a lot of code that's commented out in each run-me.sh script (which I have
officially renamed run-fault-sim and run-atpg-sim) and I was in the process of
figuring out how much original functionality each script conducts, but then the
server went down and I couldn't test it.
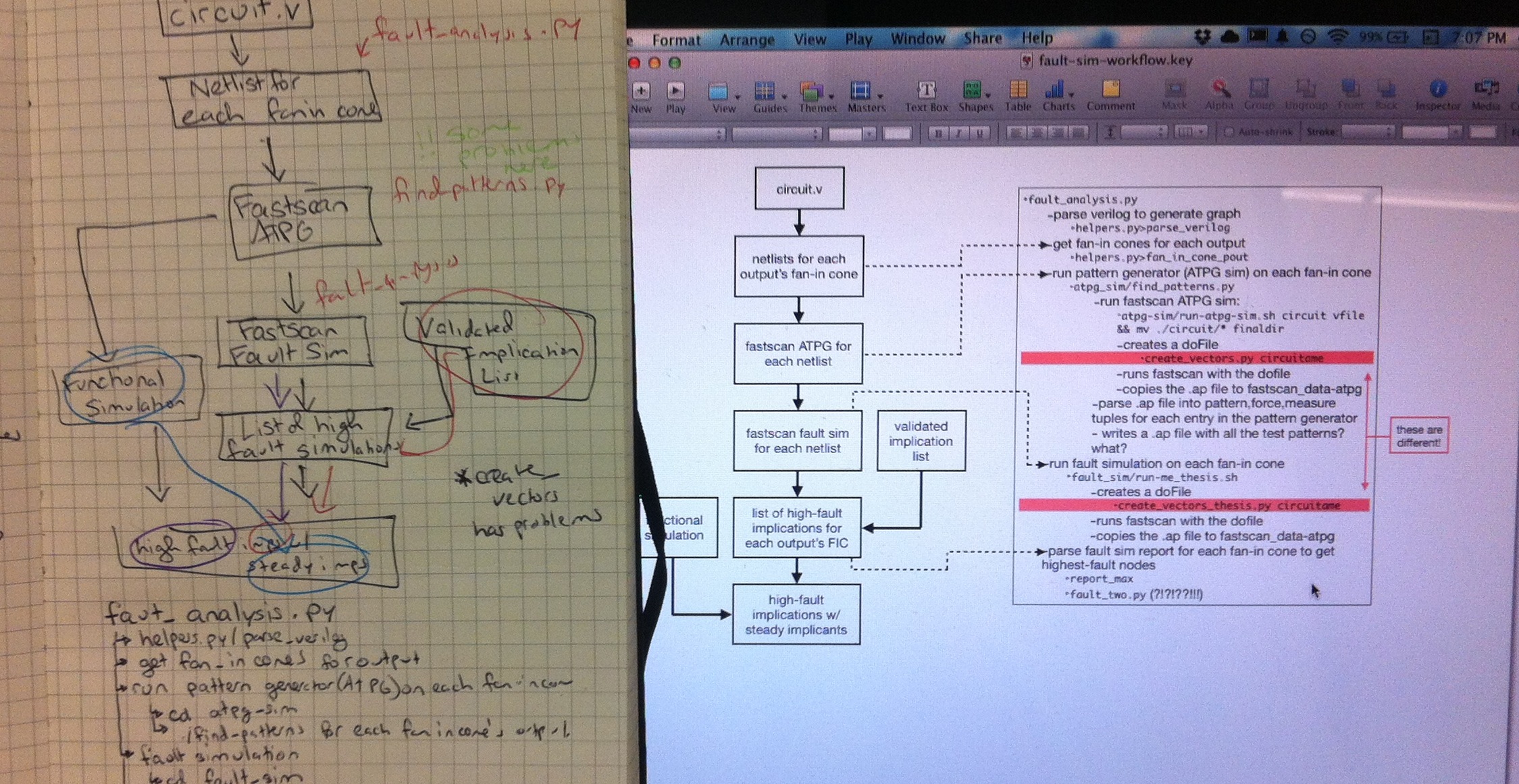
- My work for this week has effectively straddled two areas: understanding the code and understanding the simulation output files. I need to understand the code so I can fix/improve/add to it, and I need to understand what the simulation files look like so I can manipulate them as I add to the automation tools. To that end, I moved my flow-chart-to-code mapping to the 21st century and started connecting them in a powerpoint file, which was actually really useful because at some point it's easier to use a computer than pen-and-paper for outlining things. Most importantly, it really helped me visualize some of the moving parts that I couldn't figure out because of this nice same-name-differnet-folder fun. There are still some missing pieces, but I feel a lot more confident in my understanding of the code now that I could actually connected ideas to code.
Day 1 (7/1)
- Ack! Can you believe it's week four already?! I've hardly done anything! Today was productive though.
- My first order of business was to visually map out the fault
analysis code, as per all the literature proposed it would run,
and then connect steps of the verbal process with python files and
bash scripts in the various folders. It looked like this
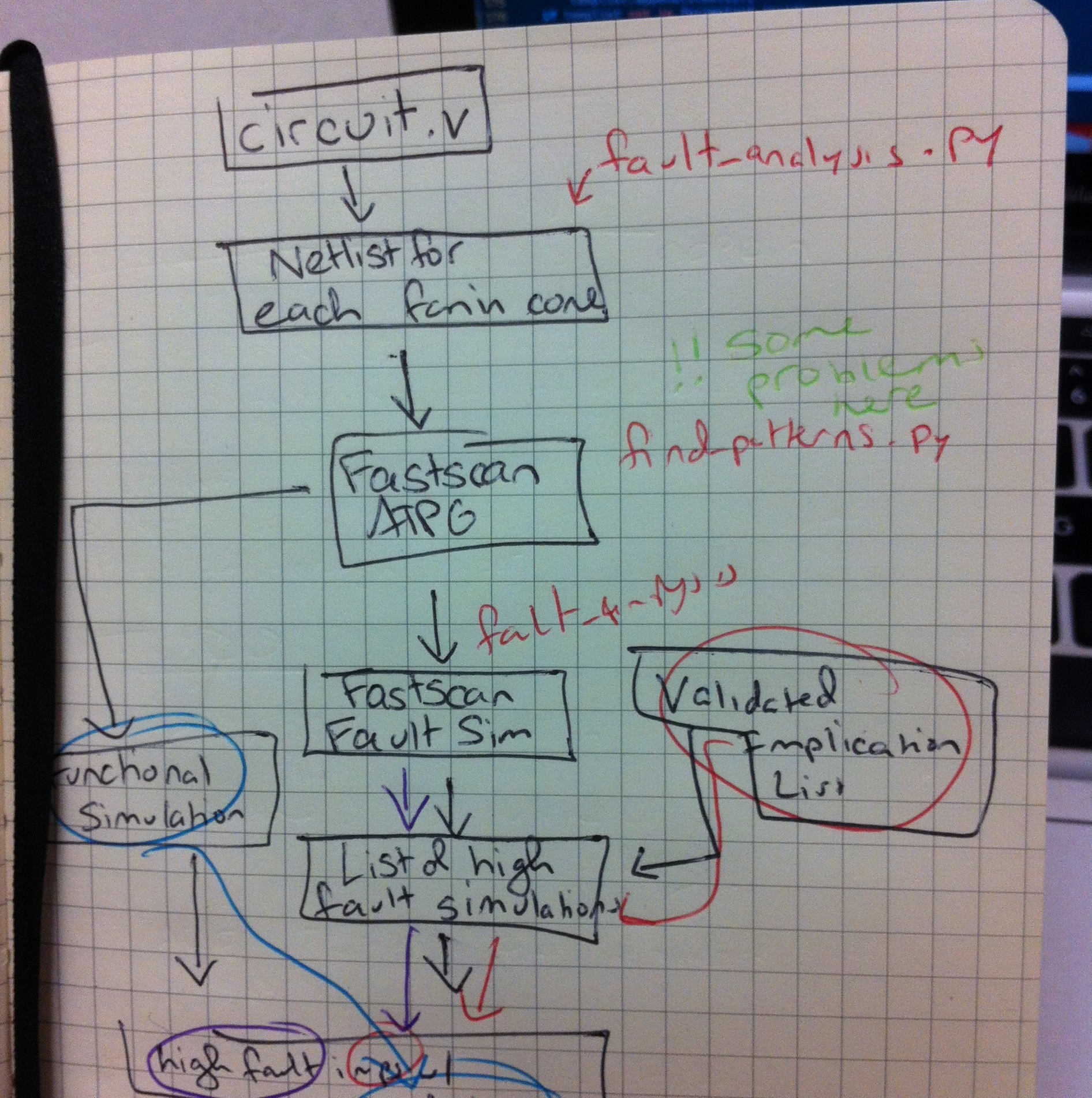 when I was done with it.
when I was done with it. - Once I felt comfortable with the order of the code execution, I went into each file and drilled down into each call for each script to figure out when everything was going. I was really happy with the progress I was making in the file when I got to the part where the fault simulations were supposed to happen. But that script kept throwing errors, and when I went to look around, I realized pretty much every functional line of code in that script had been commented out, so it was doing nothing. Why? Who knows. That's on tomorrow's TODO.
- Then, to add to my confusion, once I reached the end of what seemed to be the all-encompassing fault_simulation script, I saw it made a call to execute another script, called fault_two. What's fault_two? From my cursory investigation, it seems to be an almost exact copy of the first fault_simulation script. Why is everything happening twice? Again, tomorrow's TODO. Mysteries galore today.