


Next: Simultaneous Q-learning: No Pricebot
Up: Q-learning (QL)
Previous: Simultaneous Q-learning: One Pricebot
We can do the same thing that we did in Section 8.2 here, except now, instead of using simultaneous update we are going to use sequential update. With sequential update, if we fix one of the pricebot's actions, the Q values for the other pricebot should be twice the payoffs for the state corresponding to the fixed action. The reason that the Q values should be twice the payoffs, is that when there are two pricebots, each pricebot is going to update its price once, but update its profits twice each round. Thus, double the profits will go into calculating the Q table. This is what we see happening in Table 5. Again notice the random Q value in state 1.0 due to initial Q value updating. Again, the Q values were the same regardless of which pricebot had the fixed price.
| A. state/action |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
1.0 |
|---|
| 0.5 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.6 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.7 |
0.0002002 |
0.1752 |
0.2002 |
0.0752002 |
0.1002 |
0.1252 |
| 0.8 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.9 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1.0 |
0 |
0 |
0 |
0.003 |
0 |
0 |
| B. state/action |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
1.0 |
|---|
| 0.5 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.6 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.7 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.8 |
0.00035035 |
0.17535 |
0.35035 |
0.30035 |
0.10035 |
0.12535 |
| 0.9 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1.0 |
0 |
0 |
0 |
0.004125 |
0 |
0 |
Table 5. A. After 500211 rounds. Is in state 2 and action 5 on this round (2 = 0.7, 5 = 1.0). The old Q value - the new Q value is 0. For 0.7, wA=0.25, wB=0.75, 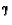 =0,
=0, 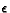 =100%. B. After 500622 rounds. Is in state 3 and action 1 on this round (3 = 0.8, 1 = 0.6). The old Q value - the new Q value is 0. For 0.8, wA=0.25, wB=0.75,
=100%. B. After 500622 rounds. Is in state 3 and action 1 on this round (3 = 0.8, 1 = 0.6). The old Q value - the new Q value is 0. For 0.8, wA=0.25, wB=0.75,
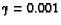 , =100%.
, =100%.
Next: Simultaneous Q-learning: No Pricebot
Up: Q-learning (QL)
Previous: Simultaneous Q-learning: One Pricebot
Victoria Manfredi
2001-08-02