


Next: Sequential Q-learning: One Pricebot
Up: Q-learning (QL)
Previous: Q-learning: Simultaneous and Sequential
If we fix the actions of one of the pricebots, so that pricebot always chooses, for example, the price 0.7, then the other pricebot will always choose prices based on Q values for actions in state 0.7. This is because, if you recall for a QL pricebot, the minimum price of all prices besides its own is being used as the state from which to use Q values in order to choose prices; if there are only two pricebots then the minimum price a pricebot will use as its state will be the other pricebot's price. Therefore, we will only see Q values other than 0 for actions belonging to state 0.7. This is basically what we see in Table 4. There is a random Q value of 0.001 in state 1.0. This is due to the initial random learning. If we were to get rid of this initial random learning then this random Q value should disappear.
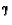 The Q values for the actions of the state 0.7 should be the same as in the payoff table when is equal to zero because the payoffs are being used as the reward in the update rule, and if is greater than zero then the Q values should be similar to the payoffs but should also take into account [3], and this is what we see happening in Table 4. Note, that the Q values were the same, regardless of which pricebot had fixed its price.
The Q values for the actions of the state 0.7 should be the same as in the payoff table when is equal to zero because the payoffs are being used as the reward in the update rule, and if is greater than zero then the Q values should be similar to the payoffs but should also take into account [3], and this is what we see happening in Table 4. Note, that the Q values were the same, regardless of which pricebot had fixed its price.
| A. state/action |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
1.0 |
|---|
| 0.5 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.6 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.7 |
0.000125125 |
0.0751251 |
0.100125 |
0.0751251 |
0.100125 |
0.125125 |
| 0.8 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.9 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1.0 |
0 |
0 |
0.001 |
0 |
0 |
0 |
| B. state/action |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
1.0 |
|---|
| 0.5 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.6 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.7 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0.8 |
0.00015015 |
0.0751502 |
0.15015 |
0.15015 |
0.10015 |
0.12515 |
| 0.9 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1.0 |
0 |
0 |
0.0015 |
0 |
0 |
0 |
Table 4. A. After 500856 rounds. Is in state 2 and action 4 on this round (2 = 0.7, 4 = 0.9). The old Q value - the new Q value is 0. For 0.7, wA=0.25, wB=0.75, =0.001, 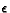 =100%. B. After 513386 rounds. Is in state 3 and action 1 on this round (3 = 0.8, 0 = 0.5). The old Q value - the new Q value is 0. For 0.8, wA=0.25, wB=0.75, =0.001, =100%.
=100%. B. After 513386 rounds. Is in state 3 and action 1 on this round (3 = 0.8, 0 = 0.5). The old Q value - the new Q value is 0. For 0.8, wA=0.25, wB=0.75, =0.001, =100%.
Next: Sequential Q-learning: One Pricebot
Up: Q-learning (QL)
Previous: Q-learning: Simultaneous and Sequential
Victoria Manfredi
2001-08-02