| Journal - Week 5 Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
|
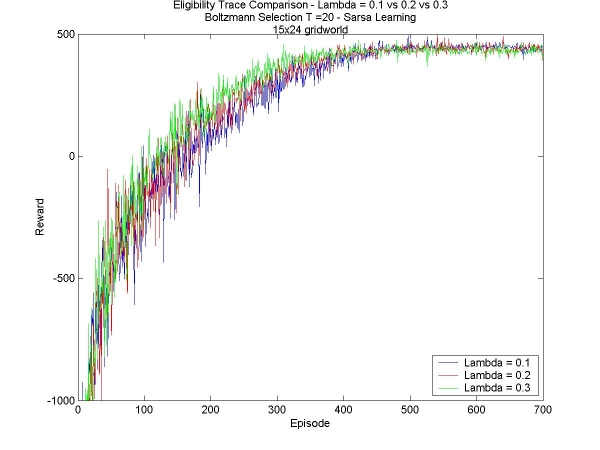
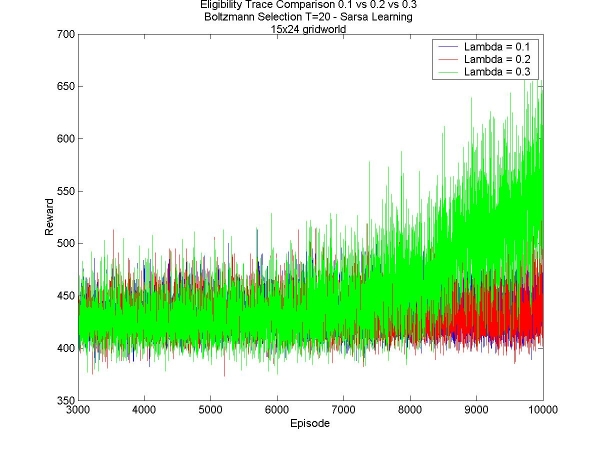
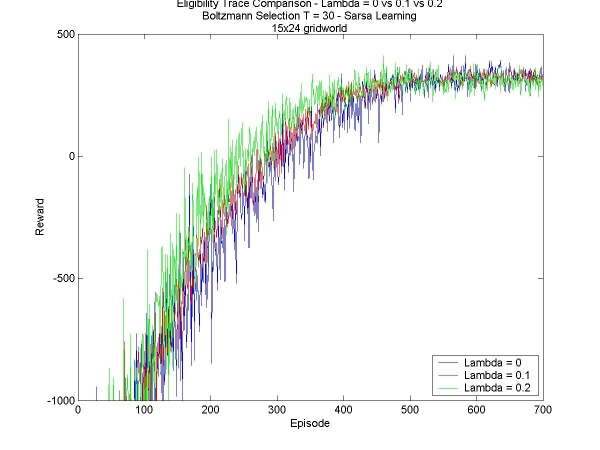
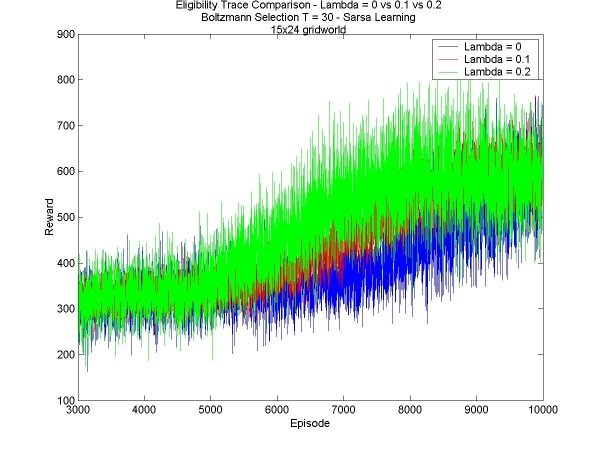
This week I added a new feature to my learning agent: eligibility traces. Rather than update only the last state-action pair seen, we update the values of the sequence of state-action pairs leading to the current state. In order to do this, each state-action pair has an eligibilty value. These are all initialized to zero, and increase, say by 1, only when a state is visited. The eligibility value decays at every time-step according to a parameter 'lambda'. The algorithm I used is described in Reinforcement Learning: An Introduction (Chapter 7, Section 5) . Coding the eligibility traces was fairly straightforward. It took a few small modification of my code, but I had it ready for debugging quickly. I tested with lambda=0, which is supposed to give the same result as not having the eligibility traces at all. Of course, it did not give me the same results, so I debugged some more and now it works fine. I am continuing at first to test in the smaller world, to get a quick idea of how the eligibilty traces affect the learning of the agent; at the same time I'm designing a bigger 30x30 world that will test the value of these eligibility traces on a 'grand' scale. The results on the small world all seems to indicate that the eligibility traces are a valuable tool. The tests are much slower (since at any time all the state-action pair values neeed to be updated), and the initial learning rates are slower, but in the end the results can be even drastically better (in the case of the small world, it found the greater reward almost half the time, rather than not finding it at all). Here are some results: Boltzmann Selection T=20: L=0.1 vs. L=0.2 vs. L=0.3 - Episodes 1 to 700 Boltzmann Selection T=20: L=0.1 vs. L=0.2 vs. L=0.3 - Episodes 3000 to 10000 Boltzmann Selection T=30: L=0.0 vs. L=0.1 vs. L=0.2 - Episodes 1 to 700 Boltzmann Selection T=30: L=0.0 vs. L=0.1 vs. L=0.2 - Episodes 3000 to 10000 For all three values of lambda, the initial learning rate is comparable (of course, higher values are still slightly slower), but that in the end, the agents with a higher lambda find the better goal much faster, thousands of episodes faster. |
||||||||||
|
Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}