| Journal - Week 4 Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
|
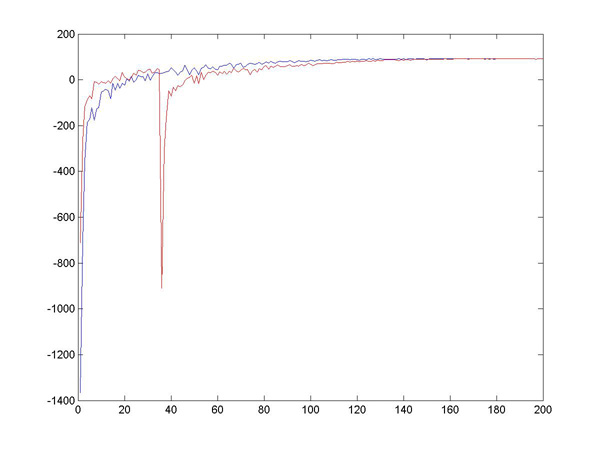
From now on the research will focus mainly on Sarsa learning agents with Boltzmann action selection. From what we've seen in the results, this seems to be the most promising. This week I'll be testing it on a larger world, and trying out a new way of updating the state-action values. A new idea for updating state-action values is to use a higher learning rate when the agent reaches a disaster situation (the same could be done when it reaches a goal state, but I am not doing that for the moment). The idea is that the agent will learn much quicker to avoid these states (or return to them). This was fairly easy to code, and gives very nice results. Once the agent has gone off a cliff once or twice, it is very unlikely to ever return there, and the following graph reflects the difference: since it avoids the cliff, it ultimately learns much faster and so gets better rewards. This is nice, in particular for Boltzmann selection, which is slower to learn. From this point on all tests are run using this idea, unless otherwise stated. Comparison between normal disaster learning rate and fast disaster learning rate The rest of the week is mostly dedicated to testing on a larger world than the simple 5x8 grid used before. Originally we were planning to go straight to a 50x80 world, but the testing took too long and I wanted to see some results. I went for a 15x24 gridworld, with a small goal nearby, and a large goal further away. Even here, the trials needed to be much much longer, 8000-10000 episodes to the 500-1000 episodes of the smaller world. This part was sometimes tedious, taking several hours per test, but once I managed to stop obsessively watching the results, it occured to me I could do other things while the tests ran. Which is nice. Here is the gridworld configuration I am testing on (orange for cliffs, blue-gray for obstacles and gold for goals): 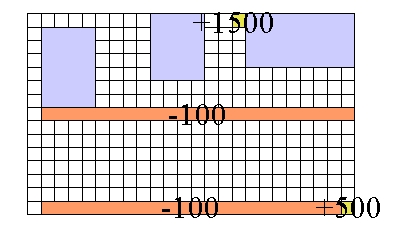
The results of the tests are really interesting. A first point I noticed is that it seems that the temperature range is more restricted on the bigger world. While a temperature T=60 on the small world quickly learns an optimal path to the goal (what it believes to be optimal), and only has poor results due to its over-exploration, a temperature T=40 on the larger world did not even have an idea for an optimal path after 12500 trials. What I found really really interesting though is the behaviour of the agent with T=30. It learns an optimal path fairly quickly, to the small, nearby goal. It's a little slower to learn that T=20, and doesn't get as good results, but after about 8000 episodes it changes its path and goes to the better reward. I found this particularly exciting, since none of the graphs I have seen have had this shape. You can click on the graph to see a larger version. 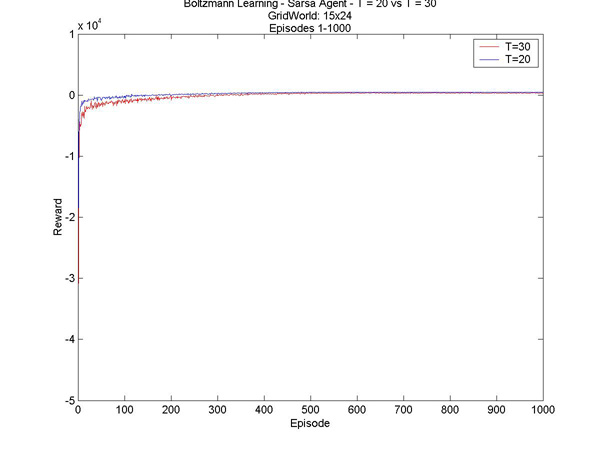
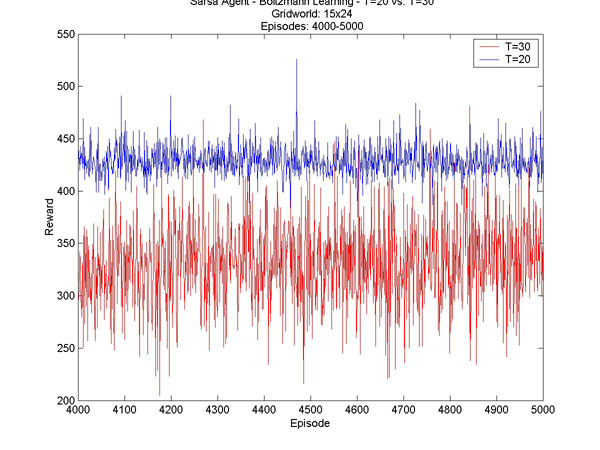
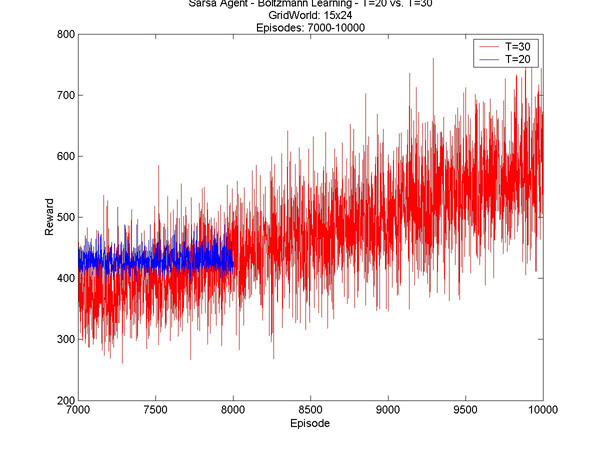
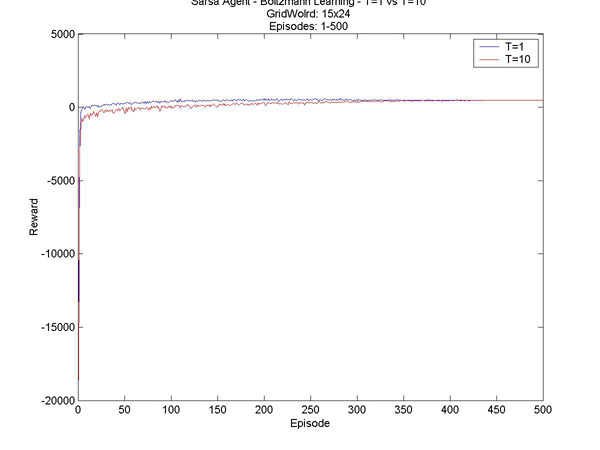
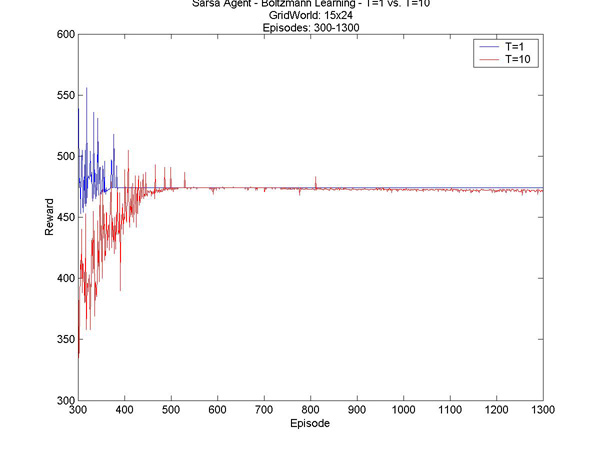
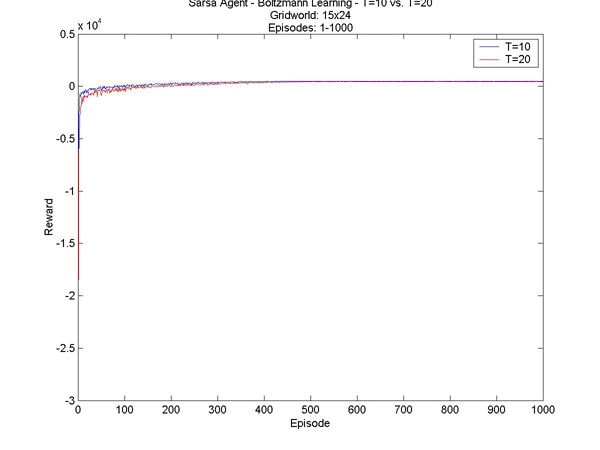
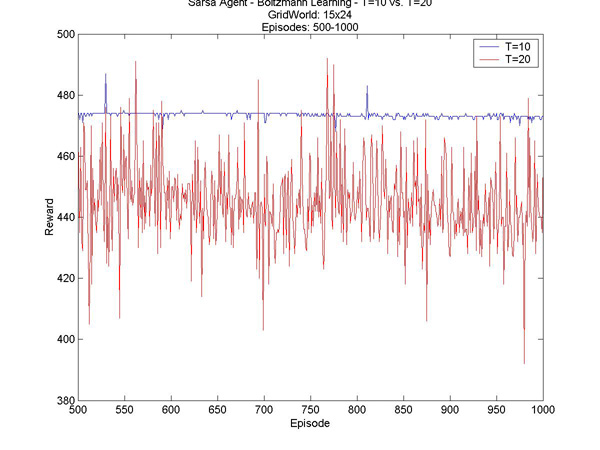
Here are a few other interesting results I graphed. T=1 vs. T=10 - Episodes 1 to 500 T=1 vs. T=10 - Episodes 300 to 1300 T=10 vs. T=20 - Episodes 1 to 1000 T=10 vs. T=20 - Episodes 500 to 1000 |
||||||||||
|
Journal: I - II - III - IV - V - VI - VII - VIII - IX - X |
||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}