WEEK 05
Switching Gears to Machine Learning - Clustering
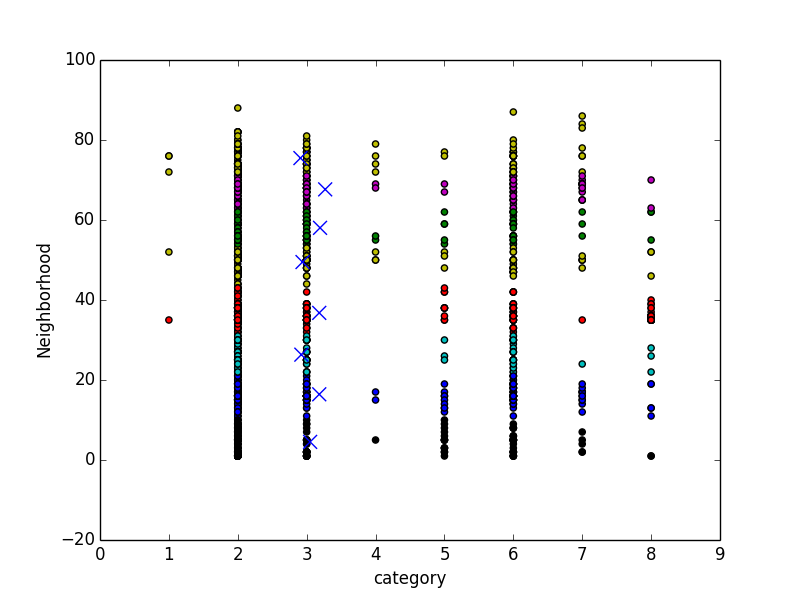
This week I switched gears from the user study to the clustering approach. After taking a few tutorial on Python scikit-learn and trying out a few clustering examples, I was ready to try clustering with our data set. Before running kMeans clustering on the data set, I needed to do some preprocessing on the data set; I scaled the data set and converted all non numeric features (description, street address, etc) to numeric. After the preprocessing, I performed clustering on different features of the data set. Fig 1 shows the clustering representation of data while considering two features - category of crime and neighborhood. The data set contains 8 categories of crime and 88 neighborhoods. The clustering accurately grouped points with same range of neighborhood together.
K Means Results For St. Louis Crime Data Set With 2 features- Category of Crime and Neighborhood