Applying an
Induced POS Tagger Model
to
English-Chinese Tag Projection
Karina Ivanetich
Department of Computer
Science
Mills College
Final
Research Report
Distributed
Mentor Project
Summer
2004
Abstract
Some
languages (such as English) are rich in annotated resources, while many other
languages experience a shortage or absence of annotated data. In addition,
human annotation, although highly accurate, is costly in terms of time and
money. One solution is to project part-of-speech (POS) tags from an already-annotated language onto another language.
This is called POS tag projection. At
present, researchers David Yarowsky and Grace Ngai (2001) are the only researchers to publish a projection
model. After modifying data projected from English to French, they obtained
promising levels of accuracy.
In
my work this summer, I began investigating part-of-speech tagging from English
to Chinese, under the guidance of Dr.
Rebecca Hwa (Department of Computer Science,
University of Pittsburgh). As a starting point, we retraced Yarowsky
& Ngai's modifications, using English-to-Chinese
POS tag projections. Since Chinese differs from English more than does French,
we are finding that Yarowsky & Ngai's model apply as well to English-Chinese projections
as it did for English-French projections. Our future work will focus on finding
additional modifications suited to English-Chinese projection.
1
Overview
Labeling
words' parts-of-speech provides useful information about languages and is
considered a necessary pre-processing step for many Natural Language Processing
applications, including machine translation. A Part-of-Speech tagger is a system that has been trained to label the words
of a corpus with POS tags. The training of this system requires tagged training
sentences (Figure One).
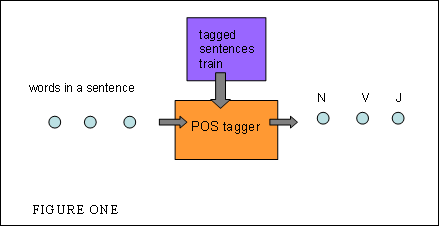
Tagged
training sentences can be generated by having a human annotate, or label, the
sentences with POS tags. This tagged text is then used as the data that trains
a tagger. One drawback to this method is that
annotation is expensive in terms of both time and money. In addition,
although tagged corpora are plentiful in some languages, including English,
these resources are scarce for most languages. While one option is to absorb
the cost of human annotation, researchers David Yarowsky
& Grace Ngai have introduced a second option:
that of projected tagging. The advantage of this option is that a resource-rich
language can be used to tag a language for which annotated resources are
scarce.
In
this option, one needs a parallel corpus, containing an annotated language L
and a second language M (Figure Two, a). The two languages are aligned (b)
through an IBM Model 3 alignment tool (see Brown et al., 1993). The tags of the
Language L can be projected onto Language M (c). Language M and its
tags can then be used to train a system to tag parts of speech for Language M ( the box under c).
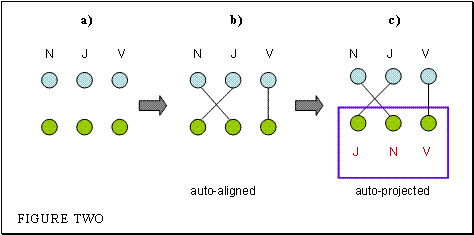
2
Prior Research
Yarowsky & Ngai
begin with an English-French corpus of parliamentary proceedings, the
English-French Canadian Hansards, and aligned it with
EGYPT, a version of the IBM Model 3 alignment tool. They then projected tags
directly from English to French. After they modified their projection process
and accuracy improved substantially. Modifications included the following:
* "Aggressive
Re-estimation"
* Subscripting Alignments of One-to-Many
Yarowsky & Ngai
found that French words were strongly centered around
one or two POS tags. They also found that the distribution of raw projected
tags to a given word contained numerous misassignments.
To correct this problem, they re-weighted the tag probability distribution for
each word so that the most frequent tag was most heavily weighted, and the
second most frequent tag had a discounted weight, and the i-th
most frequent tags (i > 2) had no weight.
This is termed "aggressive re-estimation".
Alignments
of One-to-Many are those where one English word is aligned to more than one
French word. This is a common occurrence because French is a more verbose
language than English. In their example below, a method was needed to determine
which French word, "Les" or "lois" should receive the NNS (plural noun) tag from
the English "Laws". Yarowsky & Ngai's solution is to subscript both French words according
to their position in the French compound. Then each word is weighted such that
the first word has a higher probability of being tagged a determiner, and the
second word a higher probability of being tagged a plural noun.
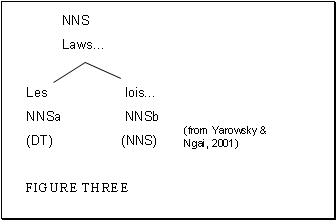
Table
One shows the accuracies of taggers
trained on different models. Each row represents the different projected models
used to train the tagger. The first was the initial, direct
projection attempt. Row two is accuracy after their modifications. Row three is
accuracy of a tagger trained on human-annotated data
and is used as an ideal, upper bound. Each column represents the different data
used to test the tagger. Column One
is the projected data, similar to the data used to train in row two. Column Two
is hand-annotated monolingual French data. Both the English-French and
monolingual French sets have been mapped to a common sets
of core tags so that they might be compatible.
|
|
tested
on Auto-Projected English-French |
tested
on Hand-annotated French |
|
Trained
On: |
|
|
|
Initial
projection |
.86 |
.82 |
|
Yarowsky & Ngai modified |
.96 |
.94 |
|
Hand
annotated |
.97 |
.98 |
TABLE ONE:
Yarowsky & Ngai’s Evaluation
of Tag Projection/Tag Induction Models. This table is an abbreviated version of
Yarowsky & Ngai's published
results.
Results
show that accuracy from initial projection starts off moderately well (82-86%).
This may be due to the fact that English and French are relatively similar. Yarowsky & Ngai's
modifications bring accuracy up to 94-96%, which is near the accuracy of a tagger trained on human-annotated data.
3
Our Research: Testing the Accuracy of English-to-Chinese Projection
Ultimately,
the goal of this work is to produce a model of English-to-Chinese projection
such that the resulting training data can produce a highly-accurate POS tagger. More locally, our goal in this work is to
investigate how well a first attempt at POS tag projection, from English to
French, will work for tag projection from English to Chinese.
3.1
Resources
The
corpus we used to project POS tags and to train the tagger
was Foreign Broadcast Information Service (FBIS). It consists of 240,911
sentences of English text, tagged by a trained tagging system, and aligned to
parallel Chinese text. The alignment tool was GIZA++, a version of IBM Model 3.
We used Chinese Treebank goldstandard mainly for
testing the tagger. It consists of 15,165 sentences
of hand-annotated, monolingual, Chinese text. Chenhai
Xi (University of Pittsburgh, Department of Computer Science) wrote the Hidden
Markov Model tagger, the program used to train the tagger, including re-estimation, and the program which
tests the accuracy of the tagger.
3.2
Data Preparation
Since the training and tagger programs require a format of Word_Tag, I wrote a formatter program that did just this. The tagged English text of FBIS contains English POS tags, while the Chinese Treebank contains Chinese POS tags. It was necessary then to map both sets to a set of core POS tags common to both. I wrote a program that takes as input English or Chinese tags with their mappings to core tags, and outputs the pre-formatted data with the new core tags. I ran this program to produce both formatted FBIS data with core tags, and formatted Chinese Treebank data with core tags.
3.3
Initial Projection
Initially
we wanted to project directly from English to Chinese. In doing so, we merely took
the POS of the English word, and projected it onto the aligned Chinese word.
However there were correspondences, other than simple one-to-one
correspondences, for which we had to make decisions.
1) One-to-None Correspondence: an English word for
which there is no aligned Chinese word (English-No-Chinese). We decided
to throw these correspondences out because there was no Chinese word onto which
we could project a POS tag.
2) None-to-One Correspondence: a Chinese word for
which there is no aligned English word (Chinese-No-English). We mapped
this missing tag to an OTHER tag.
3) One-to-Many Correspondence: one Chinese word
aligns with more-than-one English words. Recall that Yarowsky
& Ngai had the opposite issue with which to
contend. While their concern was with English alignments to the more verbose
French language, our concern is with the English language to the less verbose Chinese.
Our current projection technique is more basic however. We mapped the Chinese
word to the tag of the last English word in the compound. Our reasoning is that
many of these phrases are noun phrases and so the last tag is a noun.
4
Tests and Results
4.1
Initial Tests
Our
initial tests, featured in Table Two, accomplished two things. Firstly, it
assured us that our core tag set contained realistic granularity, and was not
too simplified. 92.7% is the accuracy of a tagger
trained and tested on different, hand-annotated Chinese Treebank sets. The tags
were the original Chinese tags. 92.9% is the accuracy of a tagger
trained and tested on the same Chinese Treebank sets, but with the mapped, core
tags. Since these two figures are very close, we know that we will not create
an artificially high accuracy level by mapping the data to an overly-simplified
set of core tags.
Secondly,
we have our accuracy level of 48.2% given a tagger
system trained our directly projected, mapped, FBIS data .
Note that this is much lower than Yarowsky & Ngai's 82-86% for direct projection. This was expected, as
English and Chinese contain more complex differences than English to French.
|
|
Test
on Chinese
Treebank |
Test
on Chinese
Treebank, Core
Tags |
|
Train
on Chinese
Treebank |
a) 92.7% |
|
|
Train
on Chinese
Treebank, Core
Tags |
|
b) 92.9% |
|
Train
on FBIS, Core
Tags |
|
c) 48.2% |
TABLE TWO:
Results from training and testing on a) different Chinese Treebank text, 14,000
and 1165 sentences respectively; b) different Chinese Treebank text mapped to
core tags, same number sentences; c) from training on FBIS and testing on
Chinese Treebank mapped to core tags, 240,911 and 1165 sentences respectively.
4.2
Filtering
With
the goal of exploring what training data leads to better accuracy, our next
step was to explore the effect of filtering on the training data. Our
preliminary study, featured in Table Three, suggested that filtering may have
some affect on accuracy. Table 2 shows the percentages of each correspondence
relative to the total number of words in the corpus.
|
None-to-One: Chinese-no-English |
20.1% |
|
One-to-None:
English-no-Chinese |
30.9% |
|
One
Chinese to Many
English |
14.4% |
|
One
Chinese to One
English |
34.6% |
TABLE THREE: Percentages of All Types Correspondences, over
all words. The first two results
suggested that filtering the amount of One-to-None and None-to-One
correspondences in the training set may have an affect on tagger
accuracy.
None-to-One
(Chinese-no-English) and One-to-None (English-no-Chinese) correspondences claim
20.1% and 30.9% respectively. Since these are non-trivial amounts, and since
these correspondences are not as simply dealt with as One-to-One
correspondences are, we hypothesized that altering their presence in the
training data might have an affect on accuracy of the resulting tagger.
In
order to filter the training data, I wrote a program that allows the user to
specify the proportions of Chinese-no-English and English-no-Chinese allowable
in each sentence. For example, one might choose to filter the training data so
that all allowable sentences contained less than 40% Chinese-no-English correspondences
and less than 30% English-no-Chinese correspondences.
Tables
Four and Five show the accuracy of the tagger after
training on variations of filtered data. All listed filtering proportions are
0.4 or less because filtering above these amounts had little affect.
Note that accuracy does increase as Chinese-no-English correspondences
decrease. However an upper accuracy of 53.9% is not terribly desirable. Recall
that Yarowsky & Ngai
achieved 94% after their final modifications. Again, this was expected in that
English are Chinese are different than English and French.
Interestingly,
accuracy actually decreases as English-no-Chinese correspondences decrease. Presently,
we cannot offer an explanation for this, although it is worth noting (in Table
Four) that when English-no-Chinese is 0.1, training set size is quite low.
|
|
Chinese-no-English |
|||
|
English-
no-Chinese |
.4 |
.3 |
.2 |
.1 |
|
.4 |
48.0 183,714 |
49.6 139,722 |
51.5 76,605 |
53.9 17,768 |
|
.3 |
48.0 162,831 |
49.4 122,302 |
51.1 64,310 |
53.6 13,265 |
|
.2 |
47.1 81,981 |
48.7 55,672 |
51.1 24,952 |
52.8 4,312 |
|
.1 |
45.2 7417 |
46.4 4683 |
48.7 2,180 |
46.1 729 |
TABLE
FOUR: Accuracy After Filtering. For each combination of training data filtered
on certain percentages of English-no-Chinese and Chinese-no-English: top
figures are the percentage accuracy of the resulting tagger; bottom figures on
the number of sentences remaining in the training set.
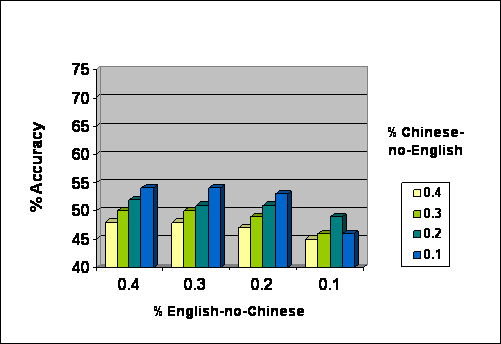
TABLE
FIVE: Accuracy After Filtering Bar Graph, created from
percentages in Table Four. Sentence length is excluded here. X-axis is the percentage
of English-no-Chinese allowed in training data. Colored bars within a group
represent the percentage of Chinese-no-English allowed in training data. Y-axis
is the percent accuracy of the resulting tagger. The
scale of the Y-axis was chosen to maintain consistency with improved
methodology in Table Seven.
4.3
RE-ESTIMATION
4.3.1
Preliminary Testing
Our
next step was to explore whether re-estimating the POS tags will improve
accuracy. Recall that Yarowsky & Ngai found success with their technique of re-estimation,
partly because of their observation that French words tended to center around one
or two parts-of-speech. Therefore re-estimating the probability weights of the
two most frequent tags eliminated some error. Our preliminary tests have
suggested that we may not find as much success with this technique for English
to Chinese projection, because the projected POS tags are not so focused around
one or two POS tags.
Table
Six shows the average number of POS tags for a word as it repeats throughout
the corpus. This figure is calculated according to a word’s frequency of
occurrence in the corpus. Table Seven shows how often the most frequent tag
occurs for each unique word. Again this was divided up by word frequency.
We
calculated these results from a file generated by the tagger
training program, which contains the POS tag distributions for each of 38,197
unique words in the corpus.

Results
in Table Six suggest that the Chinese words, unlike French words, do not focus
around a small number of projected POS tags. Words which
occur between five and one hundred times average 4.3 different tags. Words which occur one hundred or more times average 6.7 different
tags. In addition, it is unlikely that one of these tags predominates or
that the other tags are simply erroneous. The results in Table Seven suggest
that tags other than the most frequent still claim a substantial amount of
occurrences. For example, the most frequent tag for all words claims an average
59% of occurrences, but this still leaves 41% for the remaining tags.
4.3.2
Results of Adding Re-estimation
In
Section 4.2 we presented results for tagger accuracy
after training on variations of filtered data. In this section, we present
results for
tagger accuracy after both
re-estimation and training on variations
of filtered data.
In training the tagger, we followed Yarowsky & Ngai's manner of re-weighting the tag probabilites, as described in Section Two. The most frequent tag was most heavily weighted, the second most frequent had a discounted weight, and all others had no weight.
Tables
Seven and Eight show the results of these tests. Size of training set is the
same for both these and the earlier tests in Section 4.2. In comparison with the
tests in Section 4.2, accuracy has increased above those of taggers
merely trained on filtered data . The highest accuracy
obtained after re-estimation is approximately 70%, where
Chinese-no-English is 0.1 and English-no-Chinese is 0.4, 0.3, or 0.2. The
highest accuracy on filtered-only data was 53.9%, where Chinese-no-English is
0.1, and English-no-Chinese is 0.4.
Interestingly,
accuracy no longer decreases as English-no-Chinese correspondences decrease,
except for the case where both correspondence percentages equal 0.1 and size of
training set is the lowest.
Re-estimating
the weight of the POS tags in the training data did increase the accuracy of
the resulting tagger. However, we did not achieve the
higher accuracy levels of 94-96% that Yarowsky & Ngai achieved. This was somewhat expected from the
preliminary results we presented in the previous section. The POS tags
projected onto the Chinese words did not concentrate around one or two tags as
they did for French in Yarowsky & Ngai’s work.
|
|
Chinese-no-English |
|||
|
English -no-Chinese |
.4 |
.3 |
.2 |
.1 |
|
.4 |
64.0 183,714 |
66.1 139,722 |
67.7 76,605 |
69.9 17,768 |
|
.3 |
64.0 162,831 |
66.2 122,302 |
67.7 64,310 |
70.0 13,265 |
|
.2 |
63.5 81,981 |
65.6 55,672 |
67.7 24,952 |
70.6 4,312 |
|
.1 |
63.1 7417 |
64.4 4683 |
66.7 2,180 |
65.7 729 |
TABLE
SEVEN: Accuracy after Re-estimation has been implemented along with filtering
from Table Four. Top figures are the percentage accuracy of the resulting tagger; bottom figures on the number of sentences remaining
in the training set.
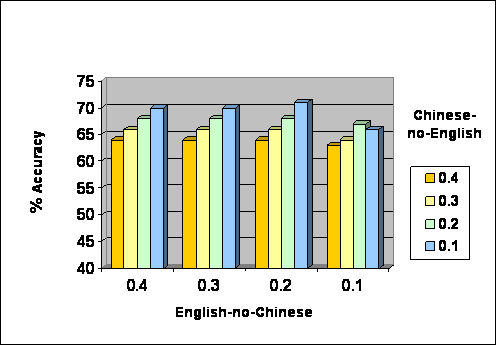
TABLE
EIGHT: Accuracy After
Re-estimation Bar Graph, created from percentages in Table Seven. Sentence
length is excluded here. X-axis is the percentage of English-no-Chinese allowed
in training data. Bars within a group represent the percentage of
Chinese-no-English allowed in training data. Y-axis is the percent accuracy of
the resulting tagger. Comparison with Table Four
shows a 16% increase in accuracy.
5
FURTHER DIRECTIONS
Our
results have shown that we will have to go beyond the current model to further
improve accuracy of a POS tagger trained on projected
data. One way to do this is to investigate the effects of reducing a
One-to-Many correspondence into a One-to-One correspondence by selecting only
the last tag. Our motivation for this decision is that these compounds are
often noun phrases. Therefore, choosing the last tag would correctly represent
the Chinese word as a noun. However it is possible that the last words can also
be Chinese punctuation words. In this case, our decision may be decreasing
accuracy. Since one-to-many correspondences make up 14.4% of total
words (Table 3), investigating
this problem may make a moderate difference in improving tagger
accuracy.
6
CONCLUSION
A
system that labels the words of a corpus with Part-of-Speech (POS) tags must be
trained with sentences whose words have
been tagged. Human annotation is costly, so it would
be advantageous if languages with plentiful annotated resources could be
used to tag other scarcely-annotated languages. An
option is POS tag projection. David Yarowsky &
Grace Ngai are presently the only researchers to
publish an attempt at POS tag projection. They projected tags from English to
French, identified and omitted or modified low-quality training data, and
obtained promising results.
In
my research this summer, we began investigating English-to-Chinese tag projection
by retracing Yarowsky & Ngai's
methodology. As English and Chinese are quite
different than English and French, we are finding, as somewhat expected, that
we need to work beyond the Yarowsky & Ngai model in order to improve the quality of the projected
training data.
After
English tags were initially projected onto Chinese in the training set, with no
modifications, tagger accuracy was
rather low (48.2%). Next we filtered the data by
selecting out sentences with certain percentages of English-no-Chinese and
Chinese-no-English correspondences. Tagger
accuracy did increase as Chinese-no-English correspondences decreased.
However
53.9% accuracy was again, not very high.
Our
next step was to re-estimate the weight of the highest two POS tags. This, combined
with filtering, improved accuracy to
70%.
In this situation, increased accuracy resulted from decreasing both English-no-Chinese
and Chinese-no-English correspondences.
In
all these instances, our results were well under those of Yarowsky
& Ngai's. This was pretty much expected, and we
attribute this most generally to the complex
differences between English and Chinese.
Further
work will include the further improvements that can be done on the projection
model to improve the accuracy of the
resulting POS tagger.
REFERENCES
Peter F. Brown, Stephen A. Della Pietra, Vincent J. Della Pietra,
and R. L. Mercer. 1993. The mathematics of statistical machine
translation: Parameter estimation. Computational
Linguistics, 19(2):263-311
D. Yarowsky
and G. Ngai, 2001. Inducing Multilingual POS Taggers and NP Bracketers via
Robust Projection across Aligned Corpora, Proceedings of HLT-2001