


Next: Q-learning (QL)
Up: Evolutionary Dynamics of Four
Previous: Myopically-optimal (MY)
The derivative-following (DF) pricebots determine their next prices by first randomly choosing a price and obtaining some profit and then randomly choosing whether to increase or decrease the price by some 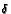 [1]. A new profit is then obtained [1]. If this new profit is more than the previous profit then the price will continue to be changed in the same direction by .
The value of
is decayed according to the following equation [1]:
[1]. A new profit is then obtained [1]. If this new profit is more than the previous profit then the price will continue to be changed in the same direction by .
The value of
is decayed according to the following equation [1]:
where
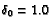 and
n0 = NumberOfRounds/10. Decaying
decreases fluctuations in price. If this new profit is less than the previous profit then the direction of price change will be reversed [1]. The derivative-following pricebots will also randomly choose a price with some probability (here 0.2; however 0.2 is an extremely large exploration rate). If this randomly chosen price yields more profit, then the pricebot will continue changing this price; otherwise, it will return to changing the price it had before it had randomly chosen a price. Without exploration, we see that the DF has a lower average price. Note that for all comparisons of the DF algorithm in the later sections of this paper, we either present the data for both using and not using DF exploration, or only the data for using DF exploration; when exploration was used, the DF algorithm always explored with probability of 0.2. The reason for using DF exploration was that the DF seemed to be able to increase their profits with exploration; this is possibly due to the increased average price [1],[2]. It makes more sense to decay the DF exploration rate rather than the ,
but that has not been implemented yet.
and
n0 = NumberOfRounds/10. Decaying
decreases fluctuations in price. If this new profit is less than the previous profit then the direction of price change will be reversed [1]. The derivative-following pricebots will also randomly choose a price with some probability (here 0.2; however 0.2 is an extremely large exploration rate). If this randomly chosen price yields more profit, then the pricebot will continue changing this price; otherwise, it will return to changing the price it had before it had randomly chosen a price. Without exploration, we see that the DF has a lower average price. Note that for all comparisons of the DF algorithm in the later sections of this paper, we either present the data for both using and not using DF exploration, or only the data for using DF exploration; when exploration was used, the DF algorithm always explored with probability of 0.2. The reason for using DF exploration was that the DF seemed to be able to increase their profits with exploration; this is possibly due to the increased average price [1],[2]. It makes more sense to decay the DF exploration rate rather than the ,
but that has not been implemented yet.
Again, note that since DF do not base their price-update on what the other pricebots have chosen as prices, it doesn't make a difference whether simultaneous or sequential update is used. Sequential update of 100 DF pricebots gives an average price of 0.75 if there is no exploration. With exploration of 0.2, the average DF price for 100 pricebots with sequential updating is about 0.76.
Next: Q-learning (QL)
Up: Evolutionary Dynamics of Four
Previous: Myopically-optimal (MY)
Victoria Manfredi
2001-08-02