Java Application
(click the image for bigger resolution)
The time given did not allow the ability to create java applets for a preview on the web of the animation of the motion of graph nodes in a force directed layout which I created.
|
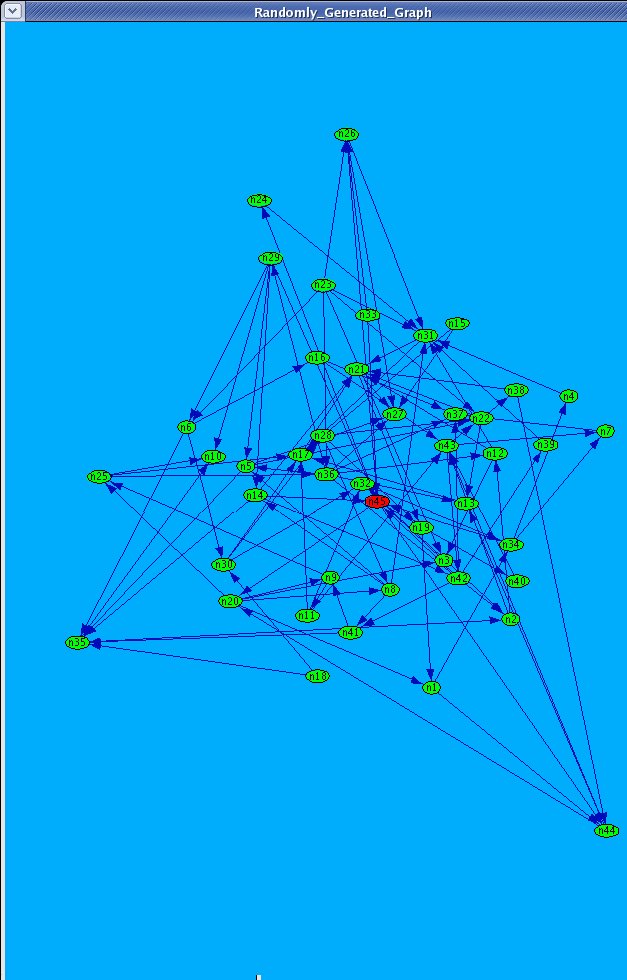 This picture represents the implementation of programs Syntetic Data Generation and Force - Directed Graph Layout |
|
|
|
|
|
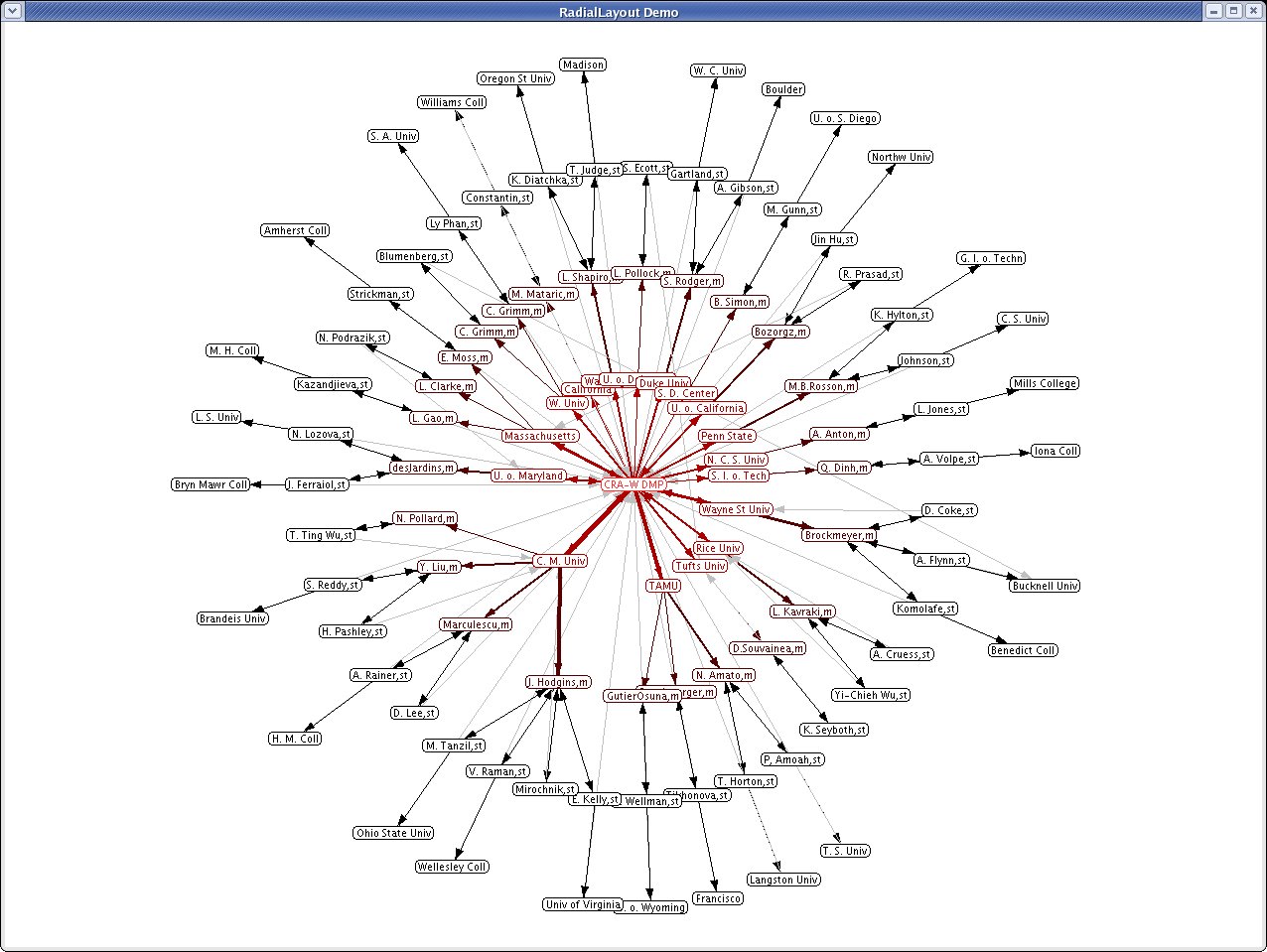
The following application was created after the development of my program GraphLaoyutN.java during fifth, sixth, and seventh week.
|
|
|
|
|
|
|
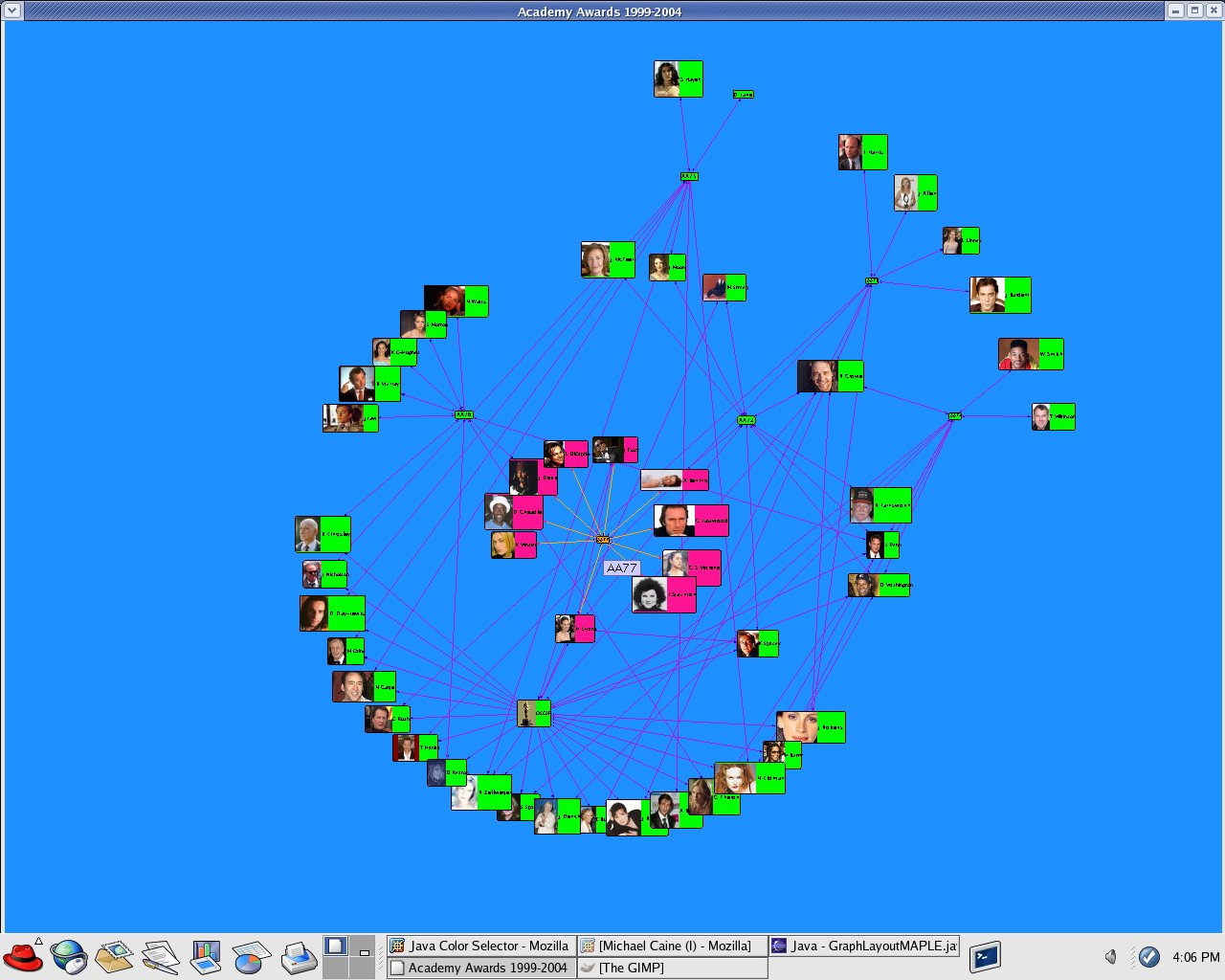
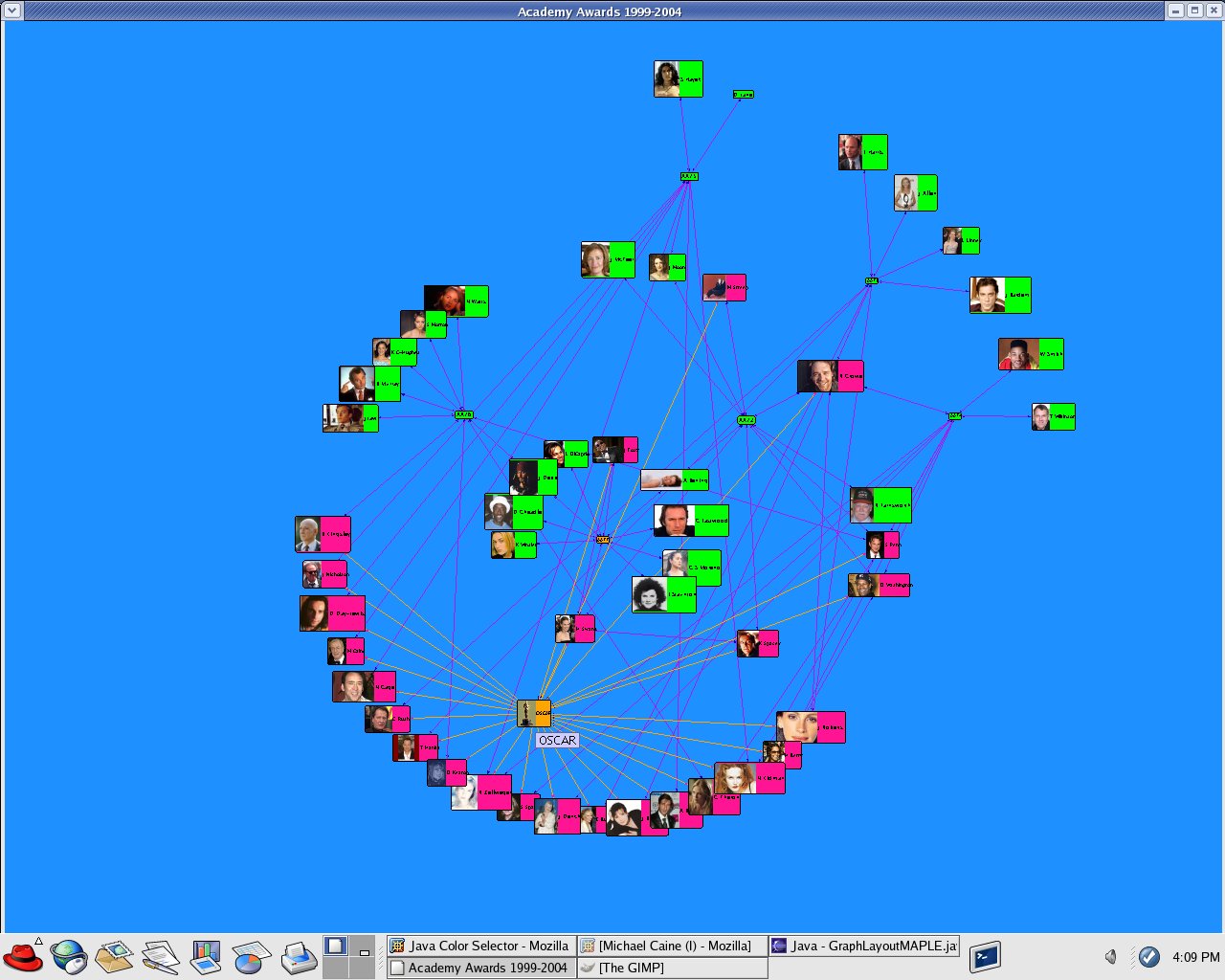
I created a new data set OSCAR_N that ran in my program GraphLayoutN.java. This dataset was based on "The Official Academy Awards Database" from http://awardsdatabase.oscars.org/ampas_awards/BasicSearchInput.jsp
|
|
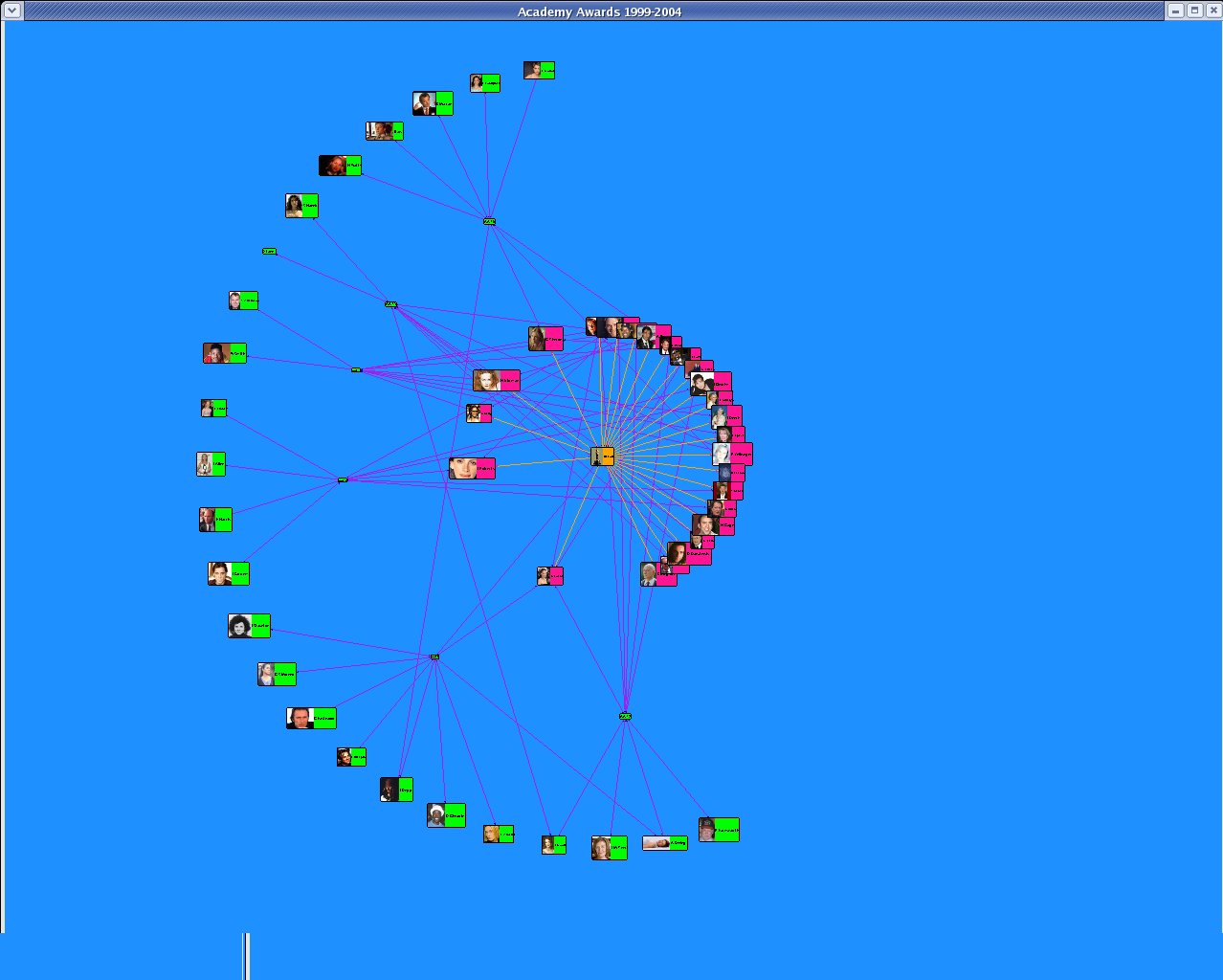
|
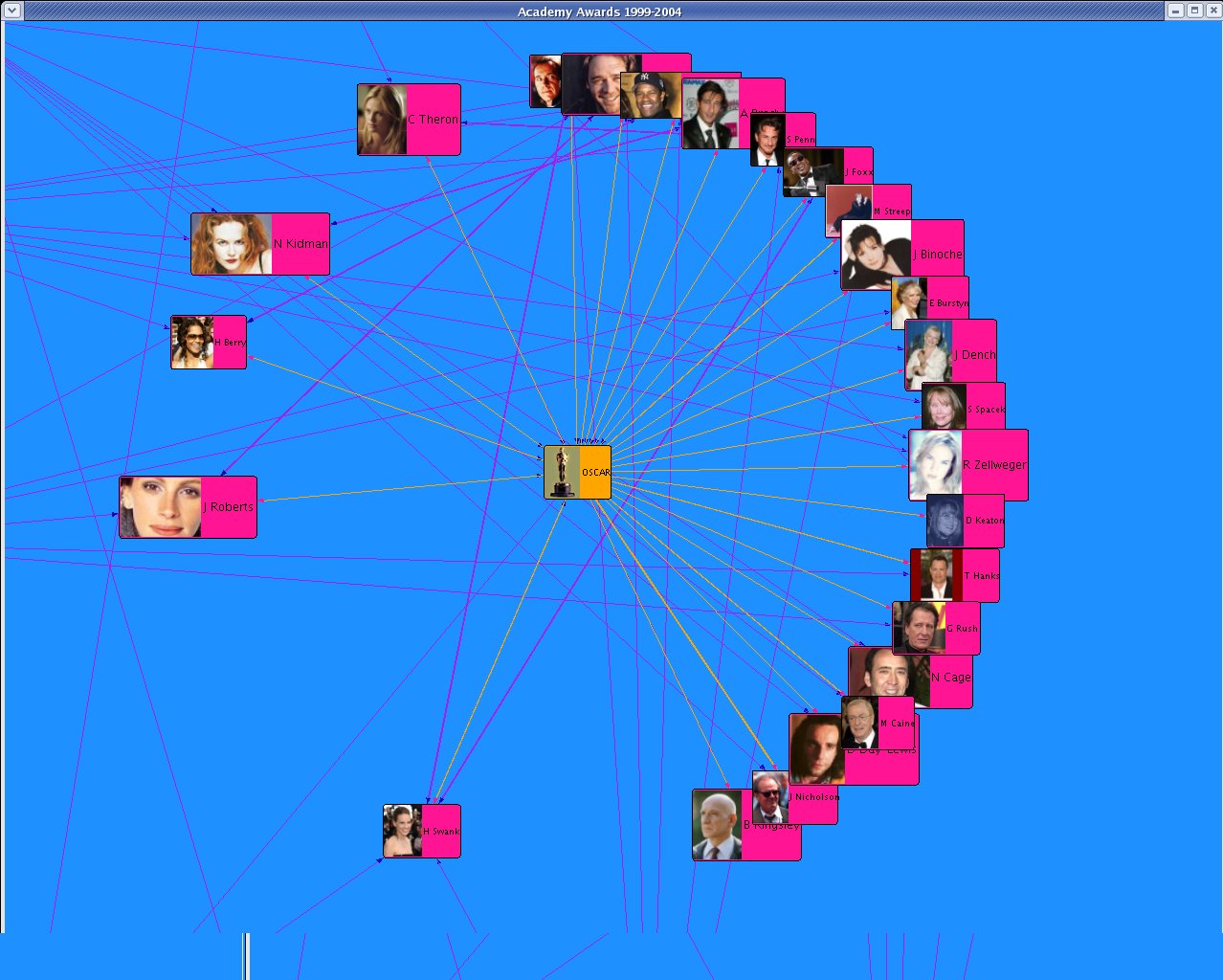
|
|
|
|
|
|
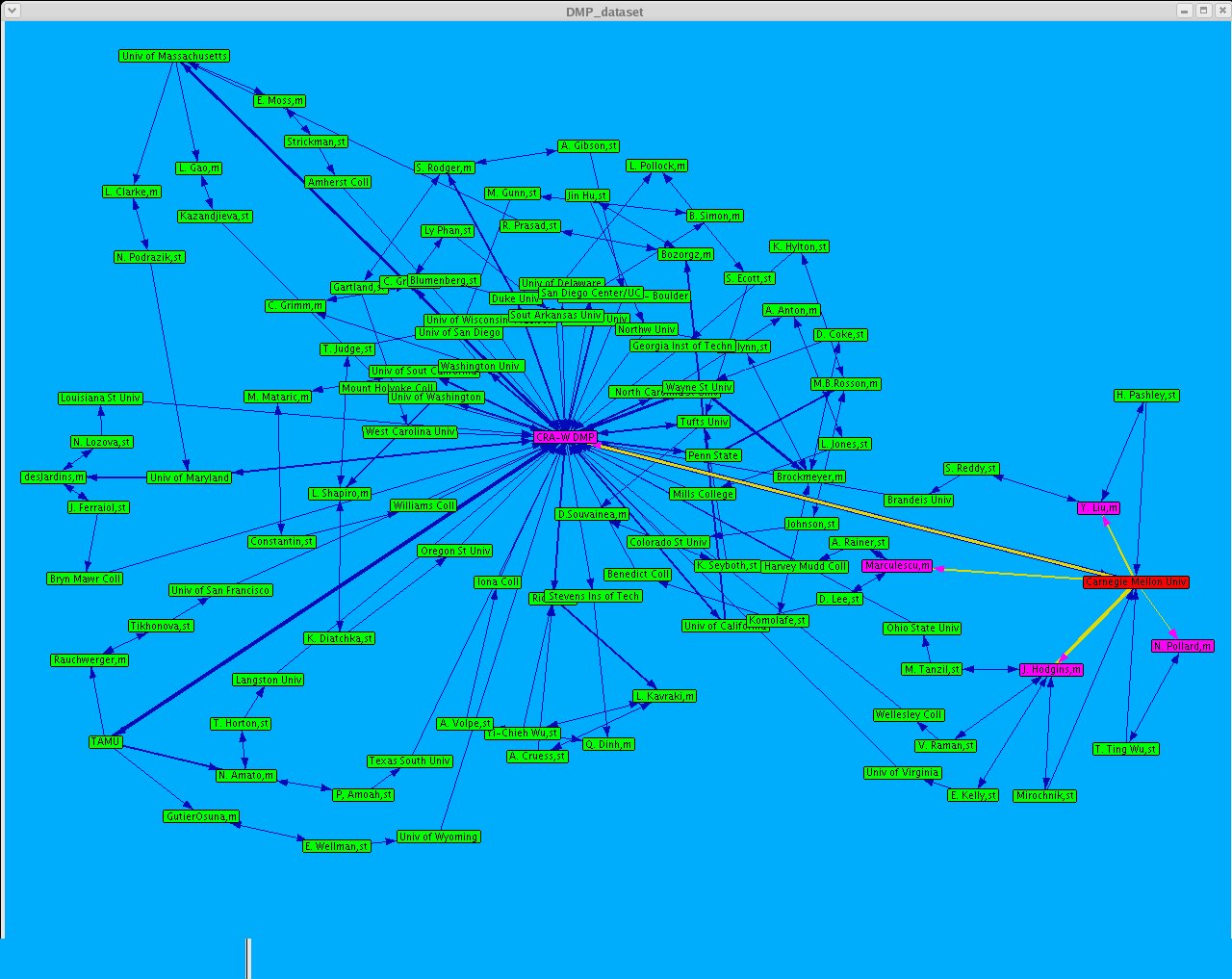
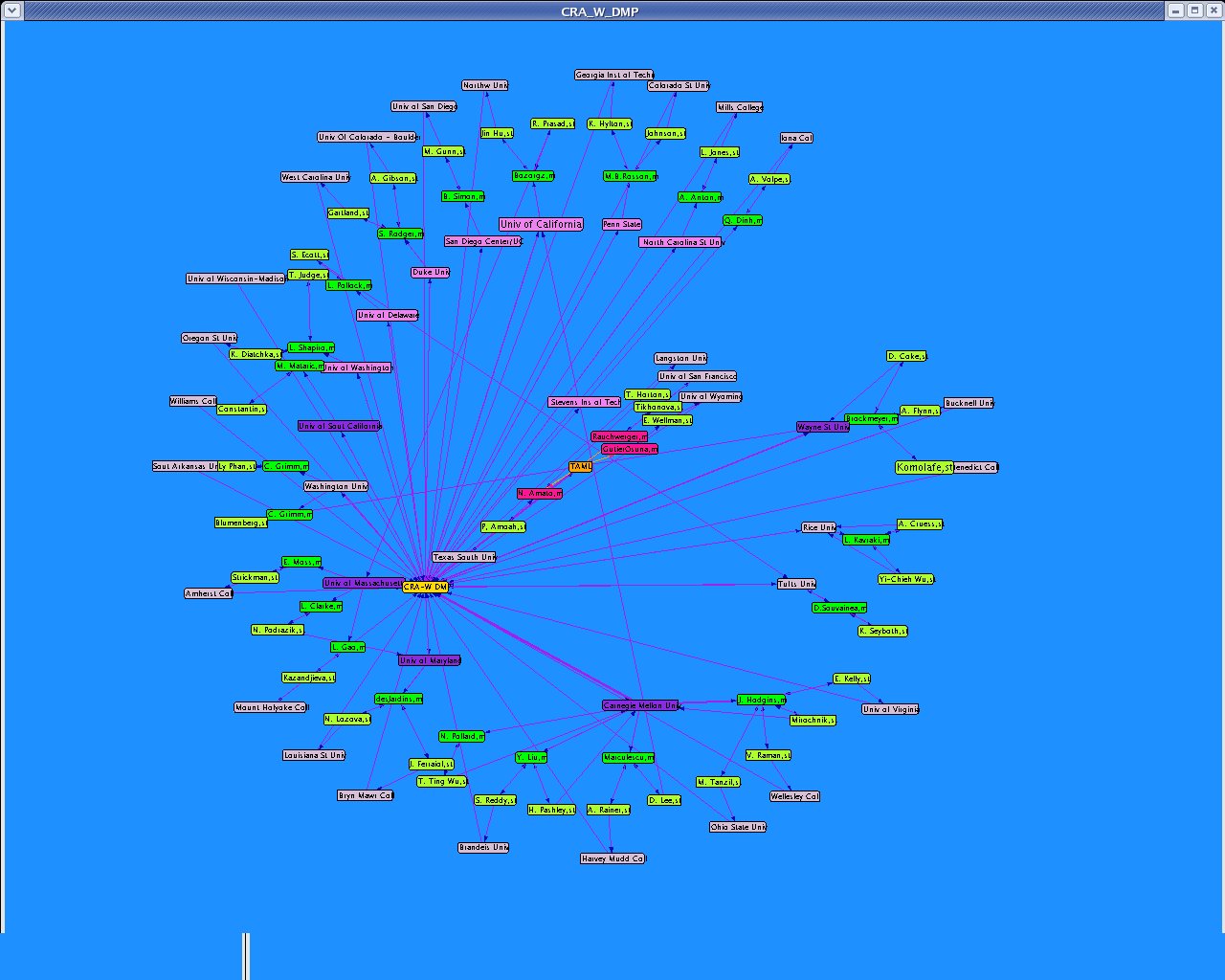
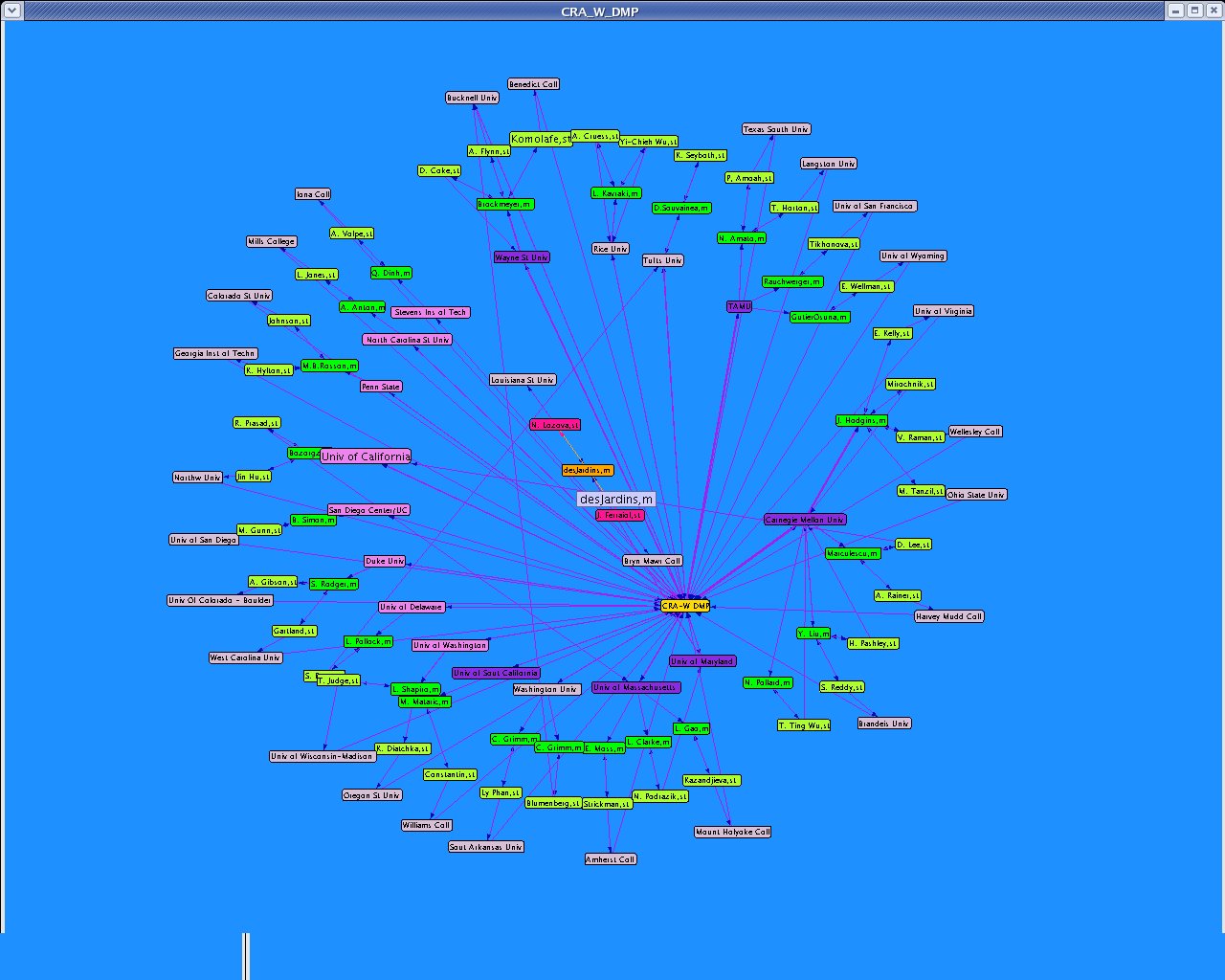
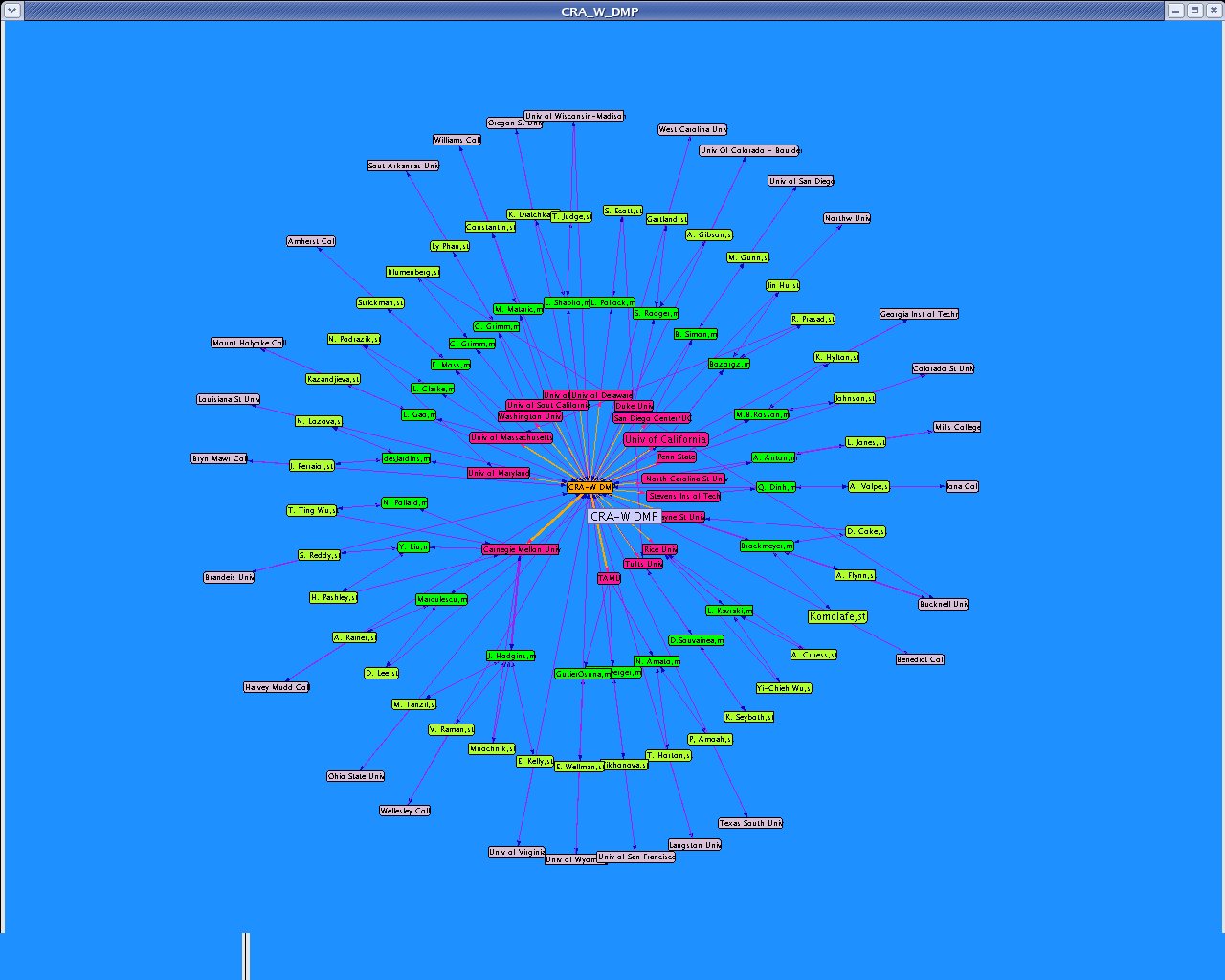
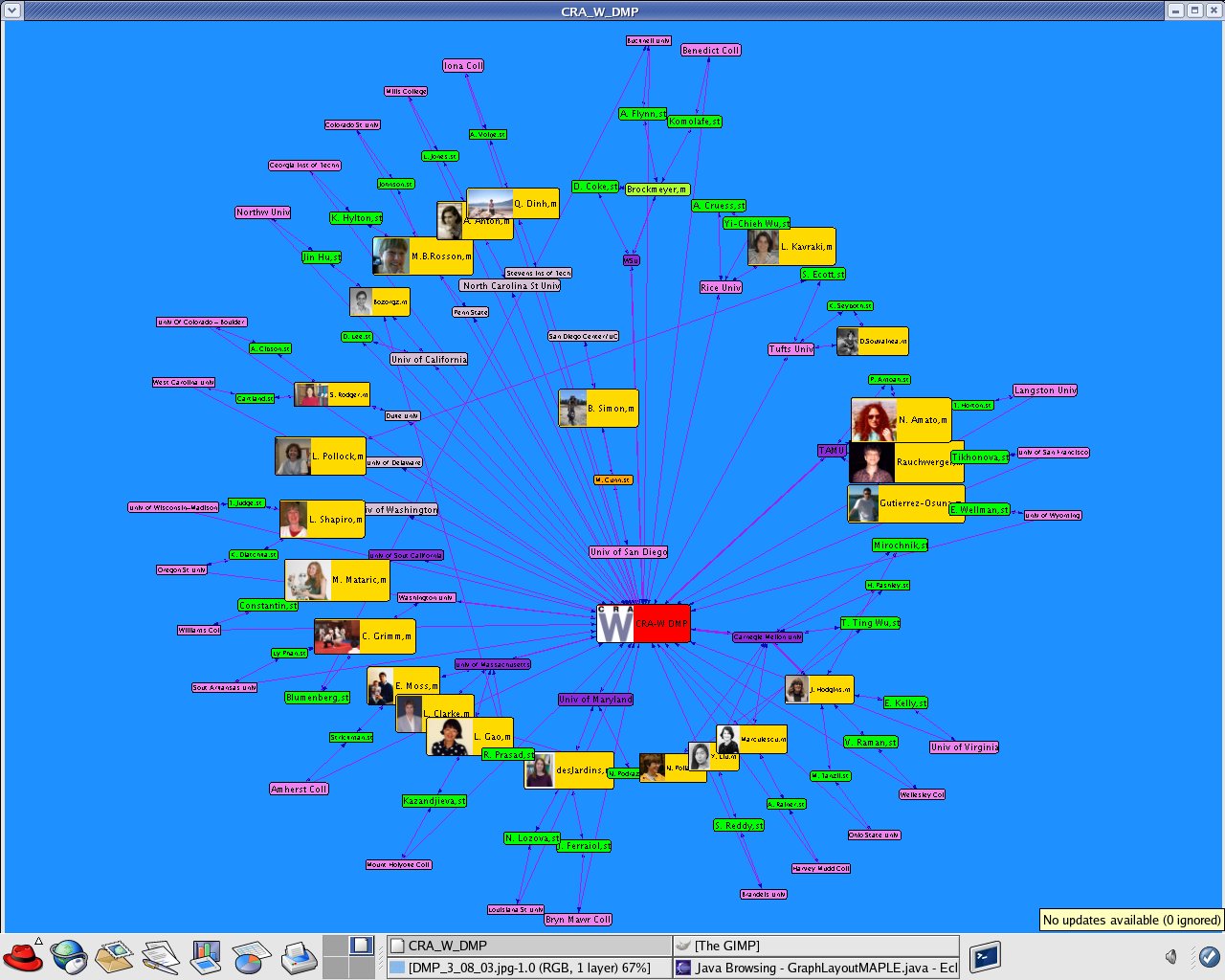
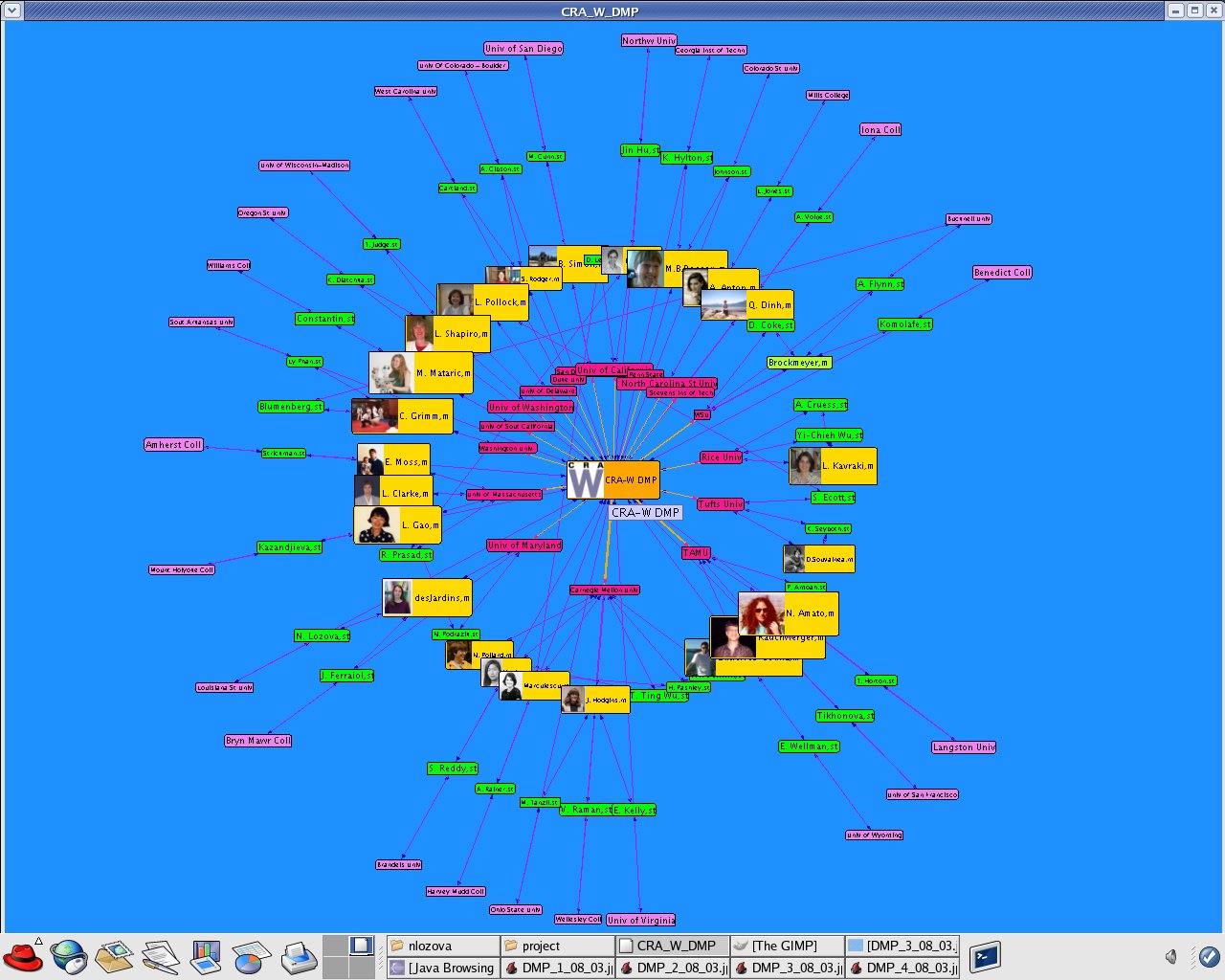
I updated the dataset "CRA_W_DMP_dataset_N.xml" using the data from the official site "Mentoring Undergraduate Women in Computing Research CRA-W Distributed Mentor Project (DMP) Summer 2005 Awards" http://www.cra.org/Activities/craw/dmp/awards/2005/2005.php and data from Academic Ranking of World Universities 2004/Top 500 World Universities from the following website http://ed.sjtu.edu.cn/rank/2004/top500list.htm
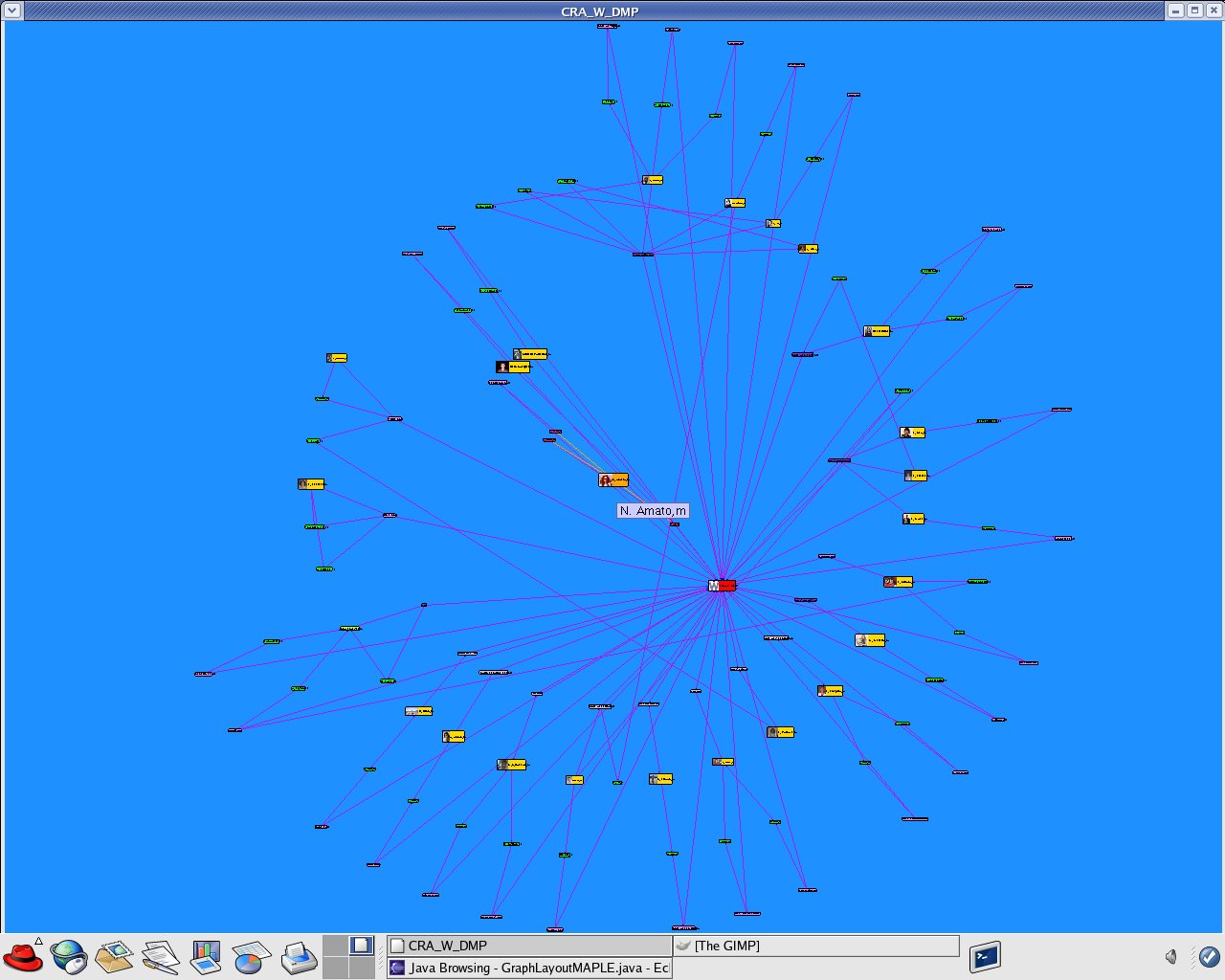
|
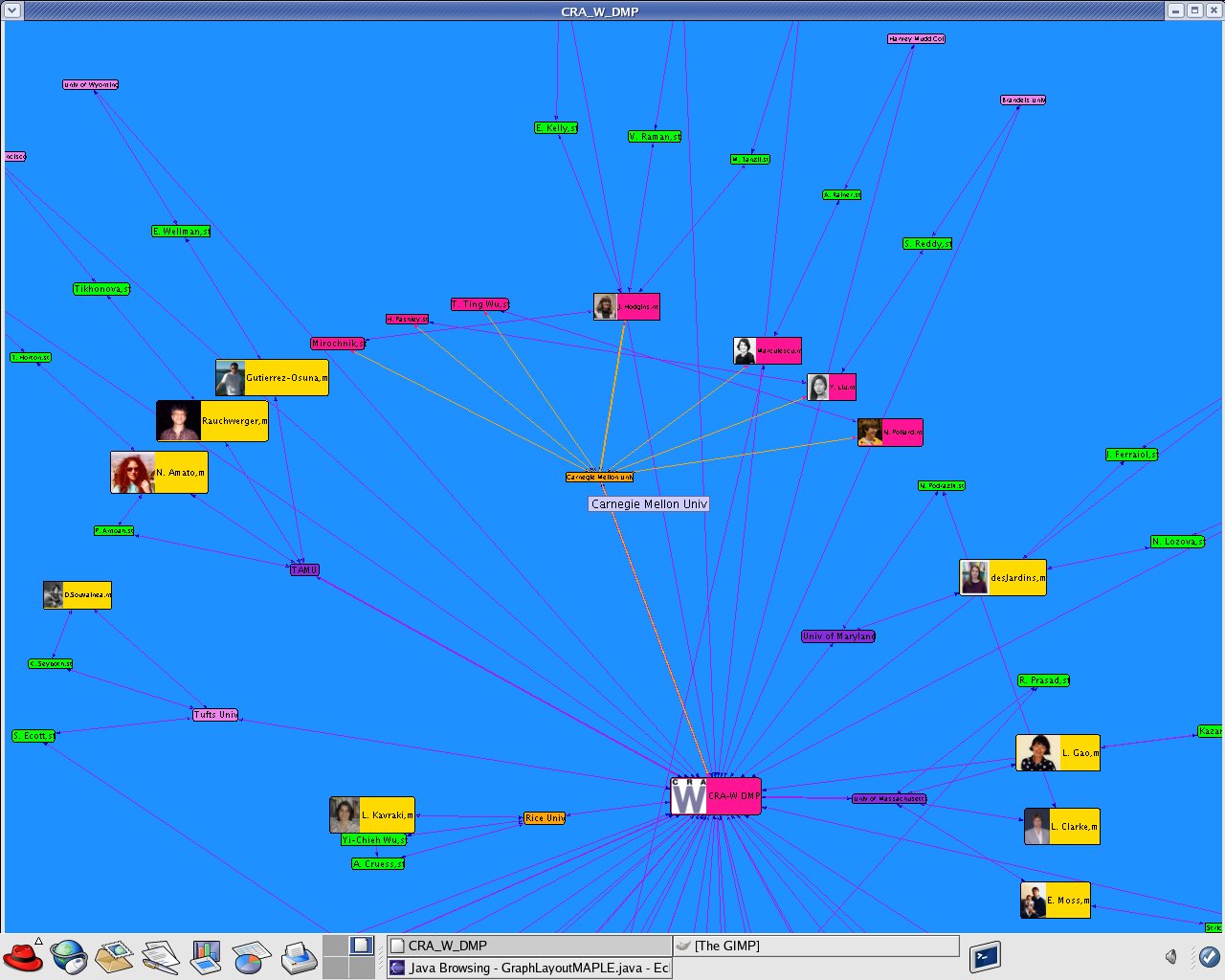
|
|
|
|
|
|
|
|
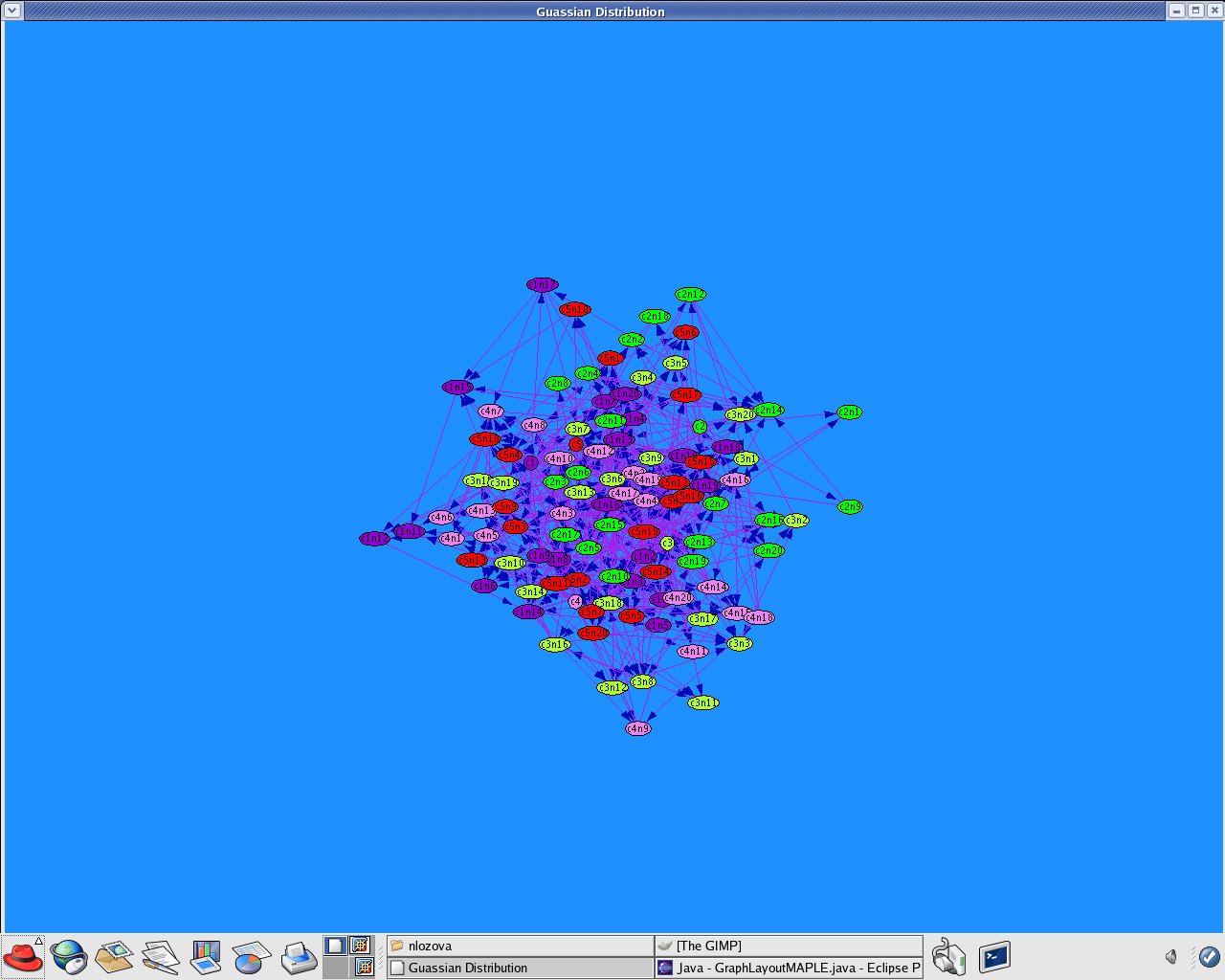
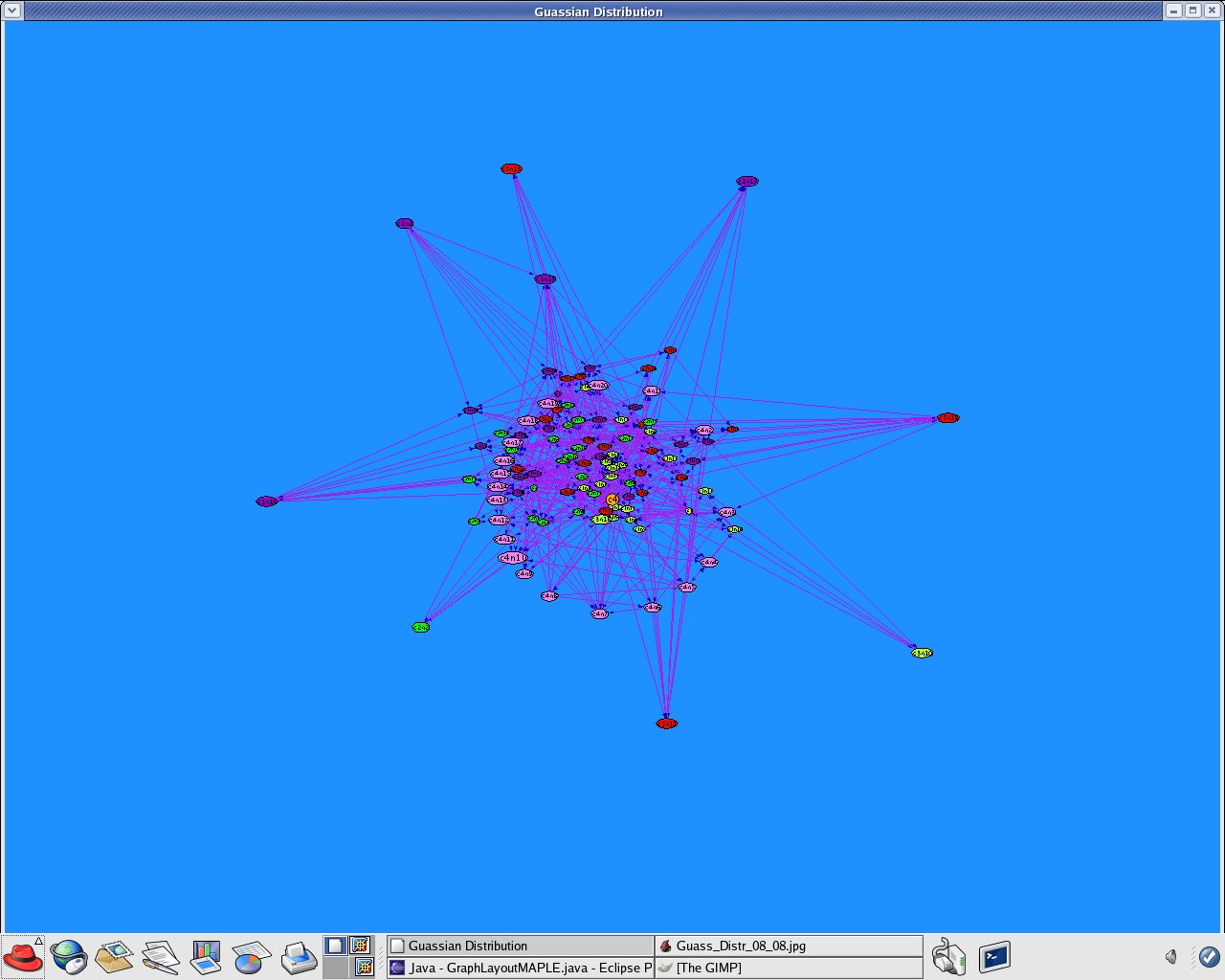
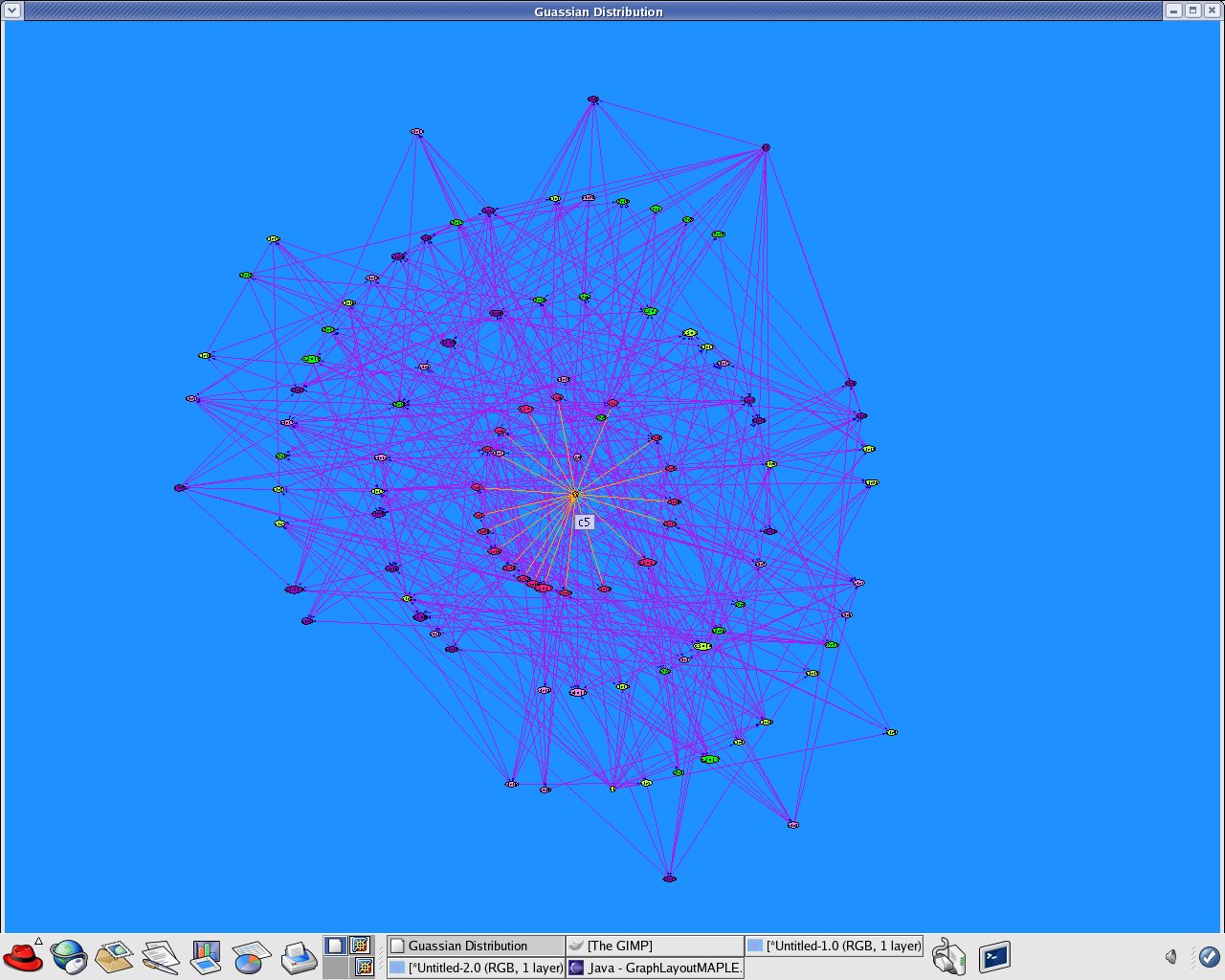
Manipulation with the created dataset, which I created during the last week of my internship, for Random clustering according to a multivariate Gaussian distribution to produce Structure-based clustering (using edges only)
|
|
|
|
|
|
|
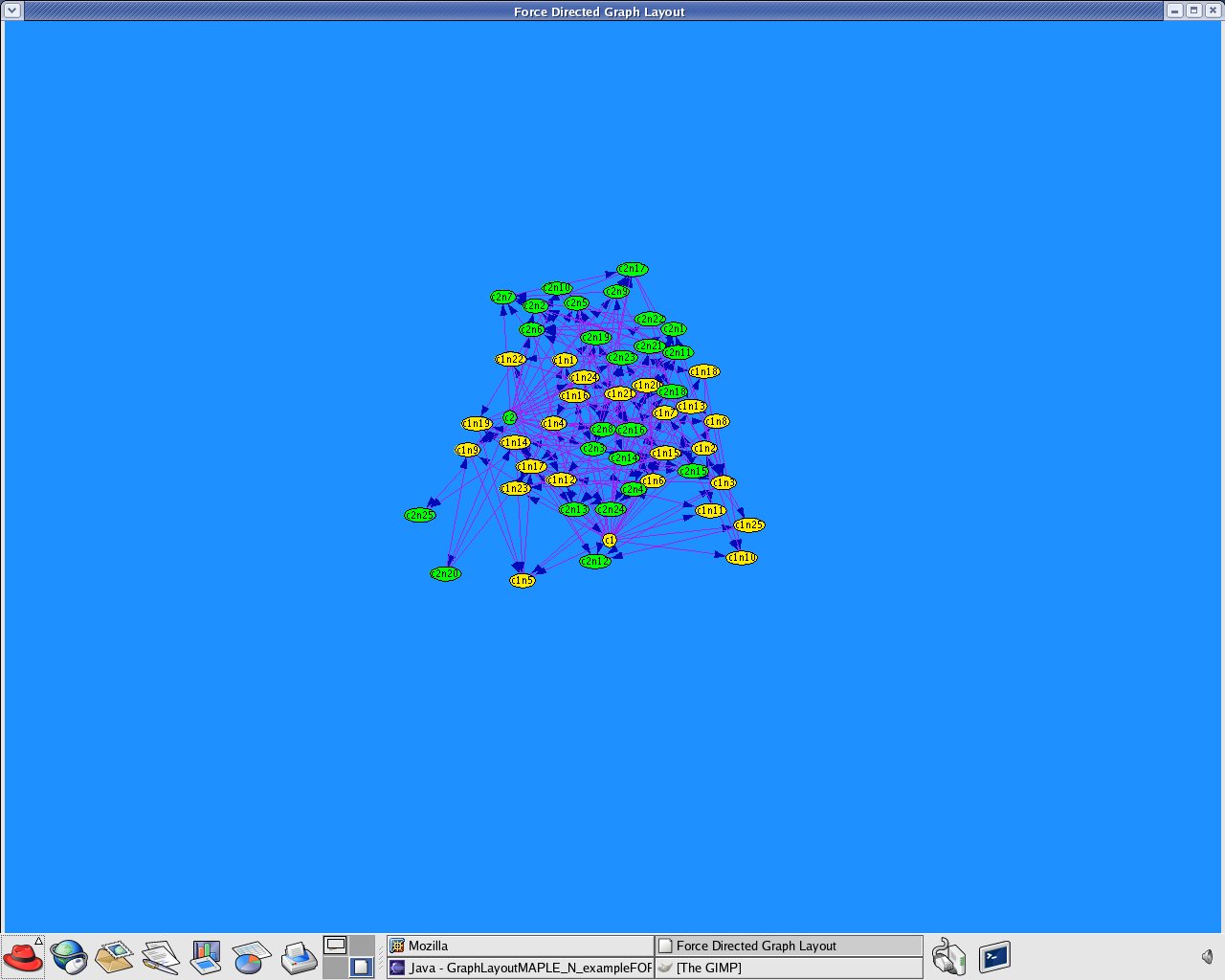
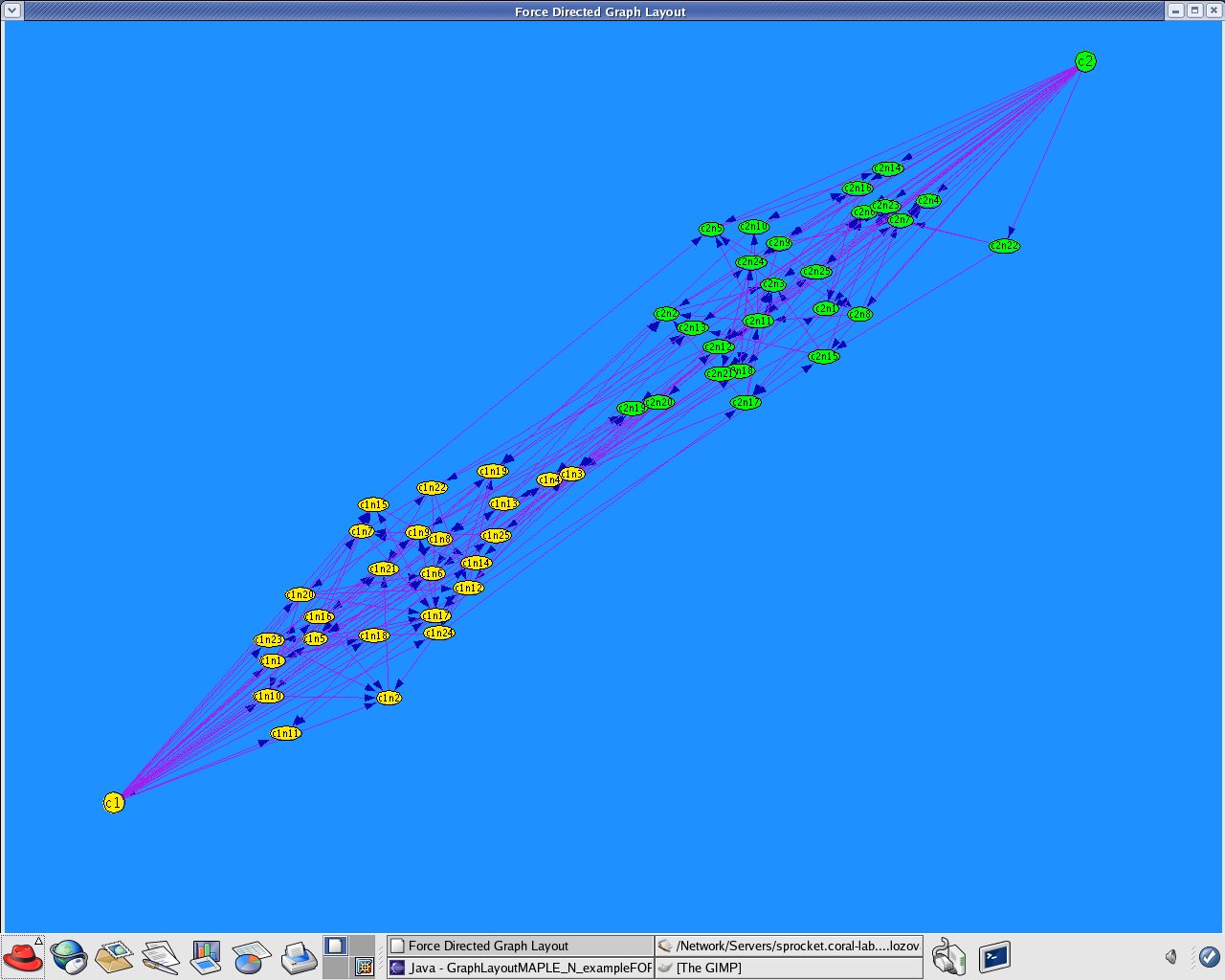
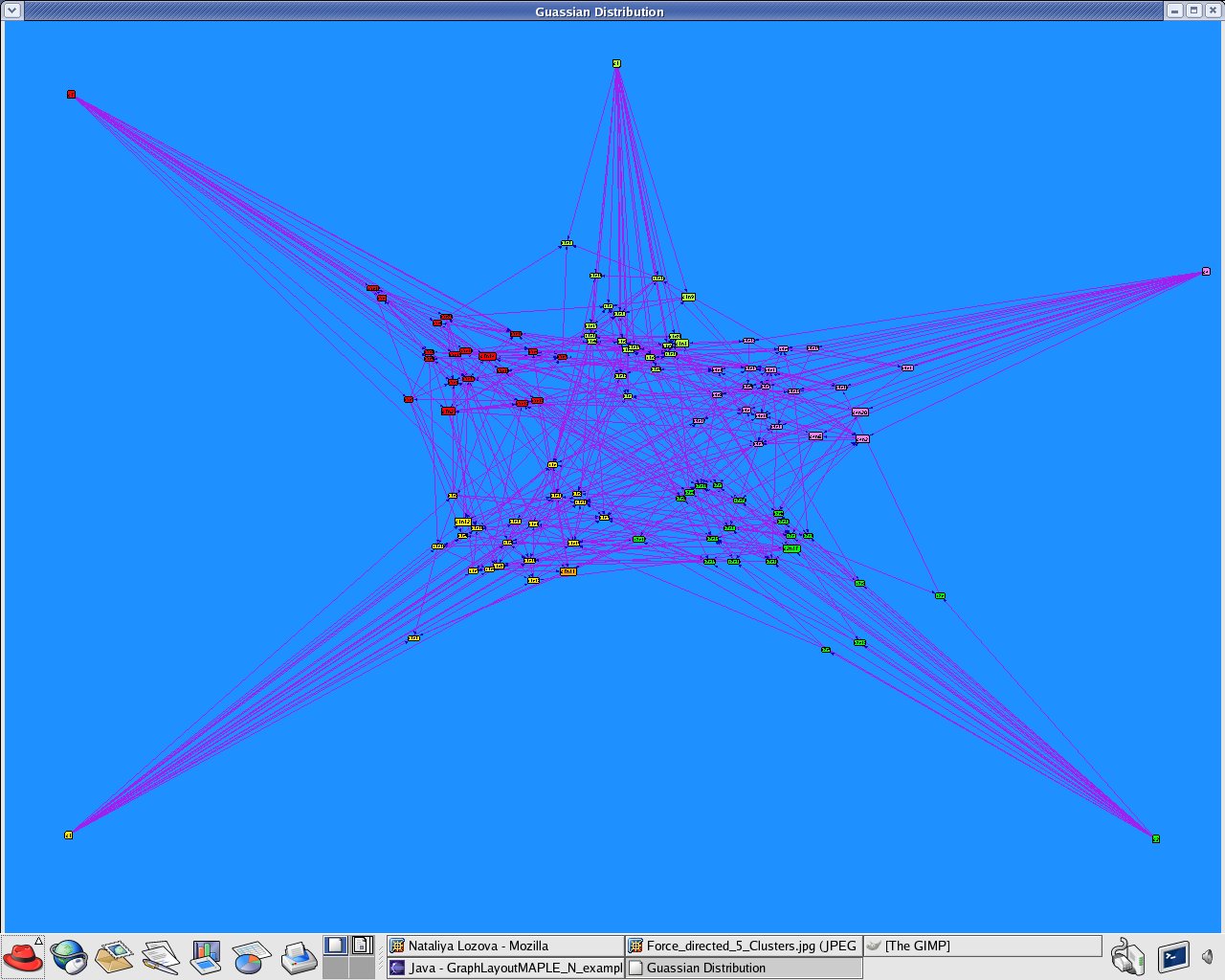
Applications that created by GraphLayoutMaple_N.java to produce Attribute-based clustering (using attributes only) with above mentioned Guassian distributed datasets.
|
|
|
|
|
|
|
Project Definitions
All of the following definitions have been cited from the websites following the definitions.