Content-Based Object Recognition--Final Report, Summer 2003
by Jocelyn Miller
Introduction
Wouldn't it be great to be able to automatically search through images on the web for that fabulous statue you just saw at the Louvre? Or even search through your own personal set of digital images to find the great picture with balloons and a birthday cake at the party you just went to? Within perhaps a minute? Or even a few seconds?
These are just a few of the motivating factors behind the problem of automated object recognition.
The roots of this project span back to at least the last 30 years of work in computer science. The ability to automatically detect and label objects in an image, something that humans do without conscious effort everyday, has evaded the capability of software developers. Progress has certainly been made in this field, from the detection of teacups to achieving levels of motion-planning after computer vision analysis. Yet, a simple query through the Google image search engine will attest to the fact that there is still a decent amount to be accomplished within this domain.
The goal of research in this domain is fairly simple. One would like to be able to segment out the various objects in a given image and correctly label each. A person could then store these tags and images in some sort of relational database in order to then run a query for sky and get back to them all the images in that database that contain sky. Or, a robot can use real-time processing to fetch the books that you just asked for.
The labelling of images can be done by hand, and has been for some time now, but that process is highly inefficient. There are too many images on the web for that to be a reasonable solution, and that limitation makes real-time processing effectively impossible.
Related Works
One of the related works is in a paper named Object Class
Recognition by Unsupervised Scale-Invariant Learning, by Fergus et al. It was the award-winning paper at the most recent ICCV conference. The method used in this paper was to learn a class of objects by first determing the interesting features of a class, and then classifying an image as part of that class if the appropriate features were present (or, enough of them to make that classification probable). Their methods found interesting features based on the entropy in the images. For instance, a bicycle has interesting features around the gears, the wheels themselves, and the handle bars. The presence of those features in the correct orientation makes the presence of a bicycle highly probable. The absence of one, (say, if one of the wheels is turned toward the view of the image, such that the circular shape is lost), might still leave enough evidence for a classifier to indicate the presence of a bicycle. It is important to note that this method is limited to classes of objects with well-defined parts.
A more indirectly related work is the work of Marina Meila. She is a professor at UW in the Statistics department, who has done a lot of work on spectral clustering algorithms. Clustering comes into play as a part of our analysis of the images in our database. A comparison between this clustering and other clustering algorithms can be seen here . More information about developments with spectral clustering can be found on Marina's homepage, www.stat.washington.edu/mmp/.
Summer Goals
The goal of this summer project was to expand upon the work of Yi Li, a computer science graduate student of Linda Shapiro, regarding content-based image retrieval. Our hope was to create symbolic signatures for the color, texture, and structure regions that Yi had segmented and to finally combine those to create a new "abstract region" for each image.
| Example of Results from Yi's Analysis | |
| An example of an image found in the ground truth database is: |  |
| That image after Yi's structural analysis can be seen here: | 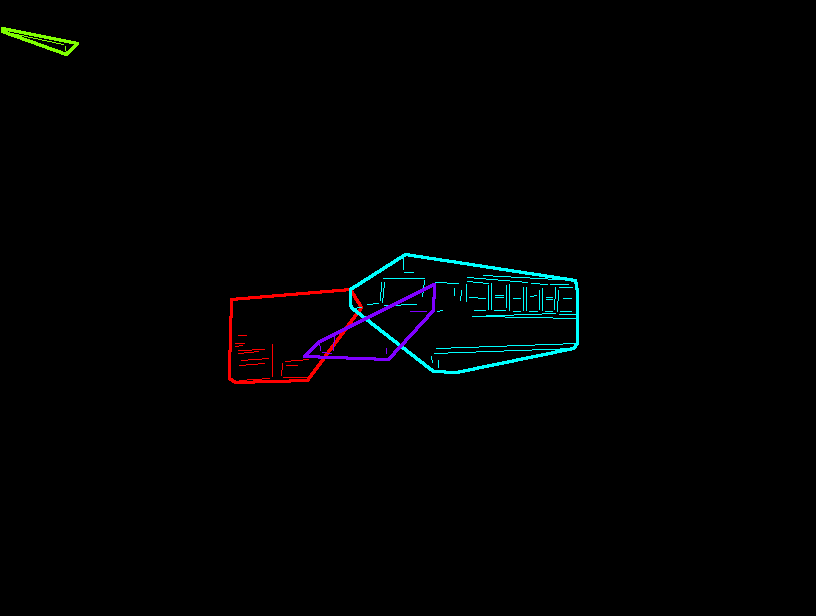 |
| The output in the XML file that was produced by Yi as a result of this analysis is in: | Structure XML file for Image 100_2031.jpg |
The more fundamental goals of the project were:
- To use an original approach to object recognition,
- To develop a method of image analysis that kept the image as abstracted as possible, thus trying to avoid learning segments of images as class definitions, and
- To keep the range of classes that we could recognize as broad as possible, (which could be easily seen as in contrast to the paper of Fergus et al.).
Experiments and Accomplishments
I used various values of a structure cluster to aid in determining what the structure analysis would be good for classifying. From each structure cluster, we extracted the density of number of lines in the region, the density of the length of lines in the region, the area of the region relative to the full image, and a length-angle histogram, in which most lines (there was an upper-bound on the length of the lines clustered) were placed into a bin dependent on their lengthb and orientation. Using just these features, we found that Sal's classifiers identified skyscrapers versus non-skyscrapers, which still had structure to them, with an accuracy of 92%. We also determined that the structure feature would not be good for distinguishing, say, buses from buildings. We decided that some additional processing, such as that of a wheel-finder, would be necessary to make those distinctions.
We then decided that we wanted to cluster the color, texture, and structure images separately to yield symbolic clusters that could then hopefully lead to abstract regions, using a clustering algorithm like k-means or spectral clustering. The plan was to use the same features for structure as we had for the initial classification experiments. For color, we would just use RGB values and for texture we would use the Gabor coefficients to cluster. I set up the program such that it would be simple to do this clustering, the plan being that another person on the project was going to provide a very abstracted kmeans function. Unfortunately, the kmeans implementation did not work, and we ran out of time to finish up that part of the work before the summer was up.
After this point, Sal and I met to discuss the situation. I brought up to him the fact that even if we had been able to group each of these different kinds of regions into clusters, it would be extremely difficult for us to detect whether the clustering was doing anything meaningful. Part of our whole approach was focused on doing as much unsupervised learning on the images as possible, but in this case that would make it difficult to discern whether semantic meaning was also being reflected in this unsupervised clustering.
The majority of the significant code for this project can be found in main.cpp. The documentation for all the data structures involved can be found under "Documentation" at www.cs.washington.edu/homes/jocie.
Conclusions
Ultimately, I think that the clustering for each of the different sorts of clusters and then using those labelled regions for classification should still be explored. Initially, the judgements as to what kind of symbolic images result from the clustering, and whether they have any correlation between the symbols and the semantics behind each of the images. If the clustering is found to be somewhat promising at that point, then more effort should be put into trying to overlap the regions and classify them with some of Sal's multi-classification algorithms.
One of the challenges is the fact that it is possible to give each pixel 3 class numbers after clustering, one for color, one for texture, and one for structure clusters, however there are too many pixels to use for classification. As the number of features grows, the amount of time for classification increases exponentially. As a result, the number of features used for classification is inherently limited, and therefore some tests need to be run after the clustering stage to figure out what are the best classifiers. Linda and I had spoken about using a kind of graph with directed edges to convey clusters that are fully enclosed by another cluster, to represent the information for one of the particular segmented images. I believe that something like that structure of features might be useful while trying to pare down the number of features. Another option is to simply use heuristics like largest clusters or clusters with the most overlap when choosing the features that will be used to classify each image.
{kind=link}