Week 1 (May 28-May 31)
- Orientation
The first day included a Smith and Campus Tour, lunch with the rest of
the research group, set up of my eecis account, activation of my lab
key, and an introduction to the project(s) I would be working on for the
summer.
- My First Project
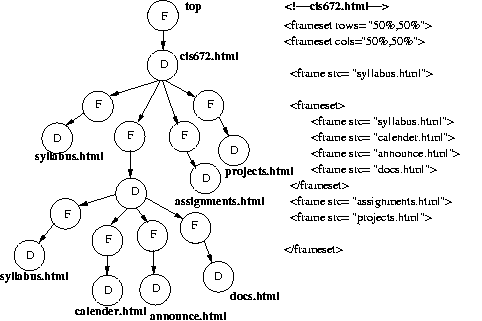
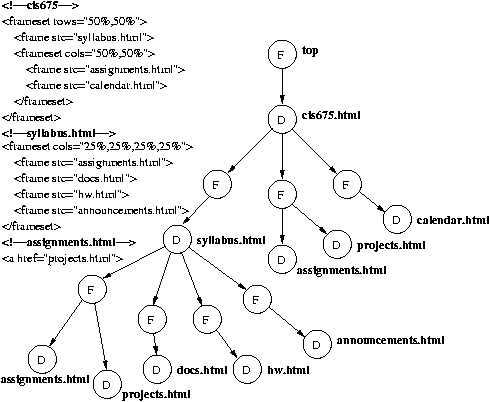
My first project revolves around the creation of a Frame Document Tree,
or FDT. The FDT is a hierarchical structure that represents the
relationships between frames and documents (or pages) in a Web
application. Sreedevi Sampath has already come up with the algorithm,
and my job is to implement the algorithm and find any holes. Parsing of
the data and the generation of nodes and edges will be handled by Perl,
and creation of the data structure and printing of the FDT will be
handled by either C++ or Java. A full description of my project can be
found at project.html.
- The Basics
It would be impossible to embark on a project without the proper
tools...
- The paper
My first item of background reading
consisted of the article Sreedevi had drafted detailing
the idea behind the algorithm and defining its elements.
- Web Applications
During orientation, Sreedevi
had given me a number of articles concerning the differences
between Web sites and Web applications and the importance of
testing these applications. In addition, she included another
piece on software testing in general. Through these articles I
was able to understand the ideas behind the Web application
environment, and re-read the paper with greater comprehension.
- JavaScript
Although I have worked with HTML for
years, I have very little experience with JavaScript (by "little
experience" I mean taking other people's code a few times and
modifying it to fit my needs). Upon Sreedevi's suggestion, I
started off my learning with JavaScript, by Don Gosselin.
I skimmed the book in general, but paid particular attention to
the chapters on windows and frames. However, I needed a more
specific resource to fully understand the JavaScript shopping
cart application that I planned to use in generating my first
FDT.
- Perl
I have had limited experience with Perl in
writing CGIs, which was a couple of years ago. However, I feel that to
take on a project of this magnitude I would be better off
getting a firm footing in Perl before proceeding. Otherwise I
risk implementing the FDT in Perl as if I were trying to do
Java. But, as anyone who has programmed Perl knows, programming
in Perl as compared to the Java way are completely
different!
- Understanding the FDT Algorithm
With Sreedevi's and Lori's help I got an understanding of the
algorithm and its basic phases. As a result, by Friday afternoon I was
able to step through the algorithm and produce an FDT of my very own
(with only a couple of extraneous nodes). At this point I felt I still
wasn't clear enough on the algorithm to implement it yet, and planned to
analyze the algorithm in depth the following Monday.
Week 2 (June 3-June 7)
- Stepping through the Algorithm
I encountered some issues while studying the FDT algorithm. For
example, the algorithm doesn't handle URLs to external sites or URLs
without targets. Further, the algorithm as yet doesn't handle
JavaScript, just HTML. Upon Lori's suggestion, I created a detailed
open issues file, and have been appending
to it anytime I encounter something the algorithm doesn't handle, or
will require special care in implementation. For example, JavaScript
has a number of complex ways to reference frames and change the current
document. I searched on the internet and found a number of scripts that
used examples of JavaScript code that may not be resolvable under the
current system, if ever, or will require further study (possibly beyond
the scope of my summer here) before implementing these features fully.
In addition, I began altering the FDT algorithm with my own suggestions
initialed in the margins. As a consequence, I was able to create my
very own LaTex file for the first time.
- Tim Toady
In my reading through the Camel (O'Reilly's definitive Programming Perl guide), the most important message I've
gleaned is TMTOWTDI, pronounced tim toady. Meaning that There's More
Than One Way To Do It. Aside from that, I have gone through most
of the basic material on operators, statements, declarations, and scope.
Next week I'll start with pattern matching.
- JavaScript, HTML's more evil friend
What nobody tells you about JavaScript that can really throw a wrench in
things! I went to Netscape's web site for the rest of the gory details
on JavaScript so I could begin to appreciate the intricacies
that make my implementation of the FDT so difficult. At this
point I plan on implementing the FDT based on HTML, without a thought
to JavaScript. Later I can begin to integrate a JavaScript module that
will at least be capable of handling the basic JavaScript issues.
- Trees and Leaves
I found a number of helpful frame examples on the internet that I will
use to help my understanding of LeafLists. In addition, I generated a
complex sample web site to test the robustness of the FDT's algorithm,
and I encountered a few issues. Foremost was the introduction of the
tree's "elbow" as a result of nested framesets. I plan on fully exploring
the elbow with more contrived frame examples next week.
- To Perl or not to Perl...
My project outline suggests that I get the tokens from the documents and
generate the nodes and edges using Perl and then use a language like
Java to build a data structure and print out the data. However, I was
having trouble discerning the fuzzy line between where use of Perl
should stop and Java begins. As a result of the difficulties involved
in finding the nodes and edges without actually making a semblance of a
tree, I have decided to complete the project in one language. Which
language, I'm not sure yet. Perl is an elegant language filled with
little programming nuances and idioms that I've never encountered
before. Although I have programmed some simple CGIs in Perl previously, I
don't have a lot of experience with the language. I have more
experience with Java, however Java can be a bit bulky. With the release
of 1.4 and a new package that handles regular expressions, Java and Perl
are both feasible languages in which to implement the FDT. The
difference being that Java may take a few hundred more lines of code to
do so. I know what Java has to offer, but I feel like Perl may be the
best suited language for the job. Either way, I will continue to
analyze the algorithm and keep reading up on Perl until I get an idea of
the best way to implement the FDT.
Week 3 (June 10-June 14)
- The FrameSet Frontier
In studying the FDT algorithm and attempting to follow it for other
examples, I realized that nested framesets are a problem. Should
framesets nested within the same page be flattened to the same level, or
should the parent frame point to an "elbow" that splits into the nested
framesets as the algorithm suggests? A consequence of the elbow is the
creation of an additional frame and document node that do not actually
exist (there is no HTML document that the frame/document nodes
represent). Further, resolution of the elbow issue is critical, so that
the frame document tree parallels the internal frame tree that
JavaScript uses within the browser. Without an accurate FDT, we will
not be able to resolve JavaScript frame references such as in the
following syntax:
- top.frames[0].frames[2].location = "HelloWorld.html"
As a result, I explored how the JavaScript frame numbering scheme
changed with nested frames within the same document versus frames that
are nested through several documents. I generated examples of my results so others working on the
project will be able to understand that JavaScript treats these
scenarios very differently.
- A Question of Trunks
While going through my contrived frame example, I found
that it can be difficult to determine the current loading frame of a document.
This is an issue when URLs don't contain target
frames. In such cases the URL is loaded into the current frame, however,
the disconnected sub trees of a budding FDT may not yet contain the
information necessary to discover the current frame that a document is
loaded into. The obscurity of the loading frame is due to the fact that
the FDT sub trees are headed by document nodes, not frame nodes. Utilizing document nodes
as the basic building block for all the sub trees is a necessity,
but the issue of finding the current load frame can be remedied. I have
added a TargetList data field to the FDT algorithm to suit this purpose. For a
given document node d, the TargetList contains a list of pages, each page
containing a URL pointing to d without a target frame and the
current frame was not known during phase 2 and the subsequent grafting of
sub trees using the LeafLists. The lack of a load edge here or there
does not greatly affect the FDT, and the resolution of the target lists
is suitable and necessary immediately following phase 2. For a given
element of the TargetList, the current frame node is resolved.
A load edge is then drawn from the current frame
node to d (the node whose TargetList is currently being evaluated).
- Effective Affectability
Sreedevi's paper states that "each frame node is distinct for a given
FDT". In terms of implementation, this is correct. However, in a valid
Web application more than one frame node with the same name may exist
(see my leaflist example). The two events
frames in my example are never within the same window, and therefore do
not cause trouble for pages who link to them. To formalize this idea, I
came up with the simple Affectable Frames
Algorithm, which I integrated into the FDT algorithm as a function.
To summarize the algorithm:
- For a given document node, traverse the tree from path to root,
marking each node along the way.
- For each document on the path to root, explore the sub frames,
marking each frame node. Do not explore any document sub trees of
documents who are children of a frame node on the path to root.
- Return the list of marked frame nodes; these are the affectable
frames for a given document node.
As a consequence, the algorithm also determines frames that could be
concurrently displayed in a given browser window. This fact makes it
possible for a web application testing suite to also test the validity
of target frames within document anchor tags.
- Jumping through the Algorithm
I have made a number of changes to the FDT algorithm. In summary:
- Elbow Problem Solved
To correct the elbow issue
(framesets that are nested within the same document) only a
small portion of the algorithm had to be removed: the portion of
the create_subgraph_frameset function that dealt with framesets.
- TargetList Resolved
I modified phase 2 of the
algorithm to include the creation of a TargetList, and the
subsequent resolution of this list in phase 3.
- Affectable Frames Installed
After developing the
Affectable Frames function, I integrated it with the FDT
algorithm by creating a new portion of phase 3. At this point
the algorithm creates affectable frame lists for all documents
in question (as decided by a revised section of phase 2) and
then uses the lists to resolve links that point to different
frames with the same name.
In addition, I have previously made the following major changes to phase
2:
- Ability to handle external URLs.
- Ability to handle URLs w/out explicit targets (hence the
creation of the TargetList).
Week 4 (June 17-June 21)
- The Divine Data Structure
Well, perhaps 'divine' is a little excessive. But after three
weeks of tiptoeing around the issue I have finally settled on a language
and a data structure with which to implement the FDT. I will implement
the algorithm in Perl, using hashes as the building block for all my
data structures.
- Hashes of Hashes of Hashes: Data structures in Perl
I cooked up some exciting structures especially for the FDT. The
data will be stored in the following manner:
- %ND
All pertinent information on the document nodes is stored in one
large hash, indexed by document name. The document name points
to an array of parent frames, an array of child frames, an array
of arrays of all the paths to root for the node, and a hash of
affectable frames whose key is the frame name and default value
as 1.
- %NF
The frame nodes are less involved than the document nodes, and
are stored in a hash keyed by frame name and pointing to a
scalar parent document and an array of child documents.
- %TargetList
The target list is stored in a hash keyed by the page that
needs to be linked. The page points to scalars of the document
whose html contained the link, and that document's parent.
- %dupes
A list of frames that have the same name is kept. It is stored
in a hash indexed by the duplicate frame name, and points to an
array of the renamed frame nodes (when duplicates are found, the
names of the frames are changed to
ParentDocName_DuplicateFrameName).
- %R
The R list, used in conjunction with the affectable frames
function, keeps track of links to pages that are in the dupes
list. The list is stored as a hash of arrays of hashes -- a hash
keyed by documents containing links that are unresolvable during
phase 2, whose value points to an array of links that are in the
document, and this array stores these links as hashes with two
elements: the reference and the target frame.
- %NE
When implemented, the external document node information will be
stored in a hash similar to %ND.
To avoid duplicate parent and children frames and documents, I plan
on changing these arrays to hashes, similar to how the affectable frames
hashes were implemented.
- Phase 1: Implemented!
Currently phase 1 of the algorithm is working. The program reads in
html files, removes comments, and creates the frame nodes accordingly.
Aside from phases 2 & 3, there are a number of things that still need to
be implemented, including:
- The program needs to be broken into separate modules, as opposed to
one huge driver program as it is now.
- The document contents of the html documents are currently stored in
memory, files should be used to make the program scalable.
- External nodes are not yet recognized and are treated differently from
internal document nodes.
- The complete path for file names should be used to allow for
sub folders within a web site.
- Duplicates nodes in child and parent arrays should be deleted.
Week 5 (June 24-June 28)
- Phase 2: Complete
To start off my fifth week, I completed most of phase 2 by linking all
URLs and creating the Target Lists and R Lists as necessary. For the
time being I am ignoring the external document nodes and treat them as
regular document nodes.
- Root of the Problem
The next step was to implement the PTR, or path to root, for each
document node. As a result of certain document nodes having more than
one parent, the PTR was difficult to implement. Therefore the
program has to keep iterating through each parent and create a new list
for the subsequent new PTRs.
- Take the A Frame
Not quite as fun as the A Train, but close. Once the necessary PTRs
have been constructed, I implemented a function that creates an
affectable frames list for as many nodes as necessary. Next I
programmed the bulk of Phase 3: resolving the target and R lists.
Affectable frames lists in theory can be generated from the frame
sub trees of children nodes, however, the program currently cycles
through each PTR and repeats the same tree traversal numerous times.
Time permitting, I hope to make this portion of the program more
efficient.
- FDT: First Draft of the Tree
Before the end of the week I had a working draft of all phases of the
FDT algorithm. For simple sites based on HTML alone, this draft will
function properly. However, there are a number of touch-ups and
improvements that need to be considered when I return for Week 6:
- Thoroughly test the last phase and ensure robustness.
- Delete duplicate entries in parent and child "arrays" (the simple
fix requires the arrays be construed as empty hashes with insignificant
values).
- Currently the program is contained in one enormous file. This file
needs to be broken into smaller module files and one driver program.
- The contents of the documents that are analyzed are currently stored
in memory; these should be stored in temporary data files to ensure
expandability.
- As of right now the program only uses document names to reference
document nodes. To account for more complex sites that store documents
in a directory hierarchy as well as for links that use full URLs even
for local pages, the full path name should be used.
- The concept of external nodes still needs to be implemented.
- Cycles that happen to occur need to be broken and reported.
- Basic JavaScript commands should be implemented.
Week 6 (July 8-July 12)
- Referees and Referents: The Process of Modularization
As one enormous document, my implementation of the FDT algorithm
contained a number of very large data structures. When breaking my
gargantuan file down into a driver program and several modules, it would
have been inefficient and resource expensive to pass all these
data structures between the functions that needed to use and sometimes
modify them. As a result, I resorted to references. By passing
references of my data structures around, I only needed to send small
scalar variables of the memory addresses to my data. So when some
functions require seven different shared data structures, I don't break
the memory bank.
- Hashes: Perl's Built-in Data Type for Sets
In Perl, sets are essentially hashes with the elements stored as keys and
insignificant values. This is precisely what I needed for my sets of
child documents and parent frames. Originally I had these two sets
implemented as arrays, unfortunately duplicates would occasionally get added and
arrays do not automatically check for repeats.
However, after implementing the affectable frames list I found it was
simpler to use a hash, rather than manually checking the array for
duplicate entries. This change created difficulties in how some
phases were implemented, specifically Phase 2 and the PTR creation.
I was forced to essentially rewrite both functions. As a result, I made
both sub routines much more precise and hopefully easier to understand. In
addition, the fact that these functions had not behaved as I had hoped
indicated that there may have been minor logical flaws that were
subsequently fixed as a result of rewriting the methods.
- An Equation for Iteration
When implementing the Target List, I realized that if one of the pages
being linked in the target list is a frames page with its own sub tree
that needs an R list and resolution with a PTR, I may need to
repeat Phase 3 a number of times. However I feel confident that with an
example to guide me I will be able to determine an equation for the
number of times Phase 3 should be run.
- Tying up loose ends
This week I concentrated my efforts on adding functionality and
reliability to my program. I was able to implement a few items on my
list, including:
- Thoroughly tested the last phase and ensured robustness.
- Deleted duplicate entries in parent and child "arrays" by changing
the arrays into keys of hashes with insignificant values.
- Broke the program down into modular pieces and one driver program.
- The contents of the documents that are analyzed are currently stored
in temporary data files to ensure expandability.
Week 7 (July 15-July 19)
- Knotting up tied ends
This week I was able to knock a couple items off my to do list (and
add a couple too). My accomplishments this week include:
- Constructed a basic README for the tool that included information
about the modules and how to run the program.
- Full path names can be used if necessary.
- External nodes implemented.
- Found two limitations thus far:
- The tool can only analyze one directory at a time.
- No frame may be named "top".
- Iterative minds loop alike
My hypothesis for the number of iterations required for Phase 3:
If there is a document on the R list that is also a document with a link
in the target list, there needs to be one more iteration. If there are
more than one but they reside in the same level of the FDT there
shouldn't need to be more iterations. However, to be expedient I
am having the program iterate through Phase 3 an additional time for
each document on the R list that is also a document with a link in the
Target List.
- Further Machinations with the PTR (Path to Root)
The bulk of my time this week was devoted to testing and improving Phase
3, specifically the find_ptr function. Most importantly, I added
cycle detection and removal to the function. While adding nodes to
the PTR, the program checks to make sure there are no duplicate document
nodes. If there are, the cycle is indicated to the user and the offending
edge that caused the cycle is removed.
- On the docket for next week
- Test the cycle detection scheme with a bigger example (a cycle that
is more than just two nodes long).
- Revise the article with the changes I made to the algorithm.
- Implement basic JavaScript.
- Test the system on some real sites.
- Finish the README file for the tool.
Week 8 (July 22-July 26)
- Cycles Turn up the Heat in a Battle for Accurate Representation
-- Researcher Baffled
Why I was banging my head against the wall last week.
When I constructed the LeafList2 Example, I was
inadvertently forced to consider frames prematurely (I had hoped to
leave cycle detection until last). In so doing, I added cycle detection
and deletion to the algorithm, but my test case was based on the
simplest cycle possible: DocumentOne.html-FrameOne-DocumentOne.html.
Next I endeavored to create a more complex cycle, with the original
title of Cycle
Example. Unfortunately, cycle detection turned out to be
exceedingly more difficult than my previous implementation. Working
with the problem all week, I was unable to find a solution. Finally, I
had an epiphany. The cycle I had created in the example involved
index.html, a child document of the top frame. The cycle was created
when index.html gained an additional parent frame, called control_frame.
The find_ptr function of my program was based on the principal that
children of the top node have only one parent frame: top. The
combination of my function and the example resulted in an unsolvable
situation that exhausted me after a week of trial and error. Finally I
realized that my example was the problem, in concert with my programming
scheme.
- Figuratively Tweaking
After modifying the algorithm, the first FDT figure in the paper needed
to be modified, as it no longer represented a scenario that would ever
occur (see the elbow problem). In addition, the
HTML code declaring the frames and framesets was incorrect, and did not
create the situation represented by the graph. I redesigned the
example
to illustrate as complex an example as possible, while hopefully
maintaining an understandable structure. After changing the code I
learned how to use the xfig tool and created an accompanying figure.
- JavaScript: Best Left for Part II?
After reading more of the paper, I feel JavaScript handling is best left
for the second part. According to the article, the FDT is based on HTML
framesets and is used to resolve frame calls with JavaScript. The FDT
created by my program accomplishes this. To the best of my knowledge,
JavaScript and other web technologies cannot create frames, they can only
link them; therefore not changing the structure of the FDT. Adding some
extra documents and links to the FDT does not change how Part II would
resolve JavaScript links, however, adverse situations could produce the
following implications:
- Any documents containing frames that are linked in with JavaScript
would affect the structure of the FDT and compromise JavaScript link
resolution.
- It is possible for a document being linked to create a cycle.
Without the find_ptr function being run on the set of document nodes,
the cycle would not be detected and could potentially ruin the program
results or loop infinitely, both of which would be most unfavorable.
Furthermore, adding JavaScript links to the FDT would require all script
elements to be analyzed by a scaled-down version of JavaScript's parser
(Rhino is such a parser and is available for download on Mozilla's web site). Already a
requisite of Part II, this time-consuming process would be a waste of
man hours and execution time to perform twice within this system.
- Accomplishments
- Re-wrote relevant portions of the article.
- Decision not to load the FDT into a Java data structure for Part II
based on the fact that I don't know how Part II will be implemented yet.
- Updated README with detailed information about the test cases,
current limitations of the program, and the issues addressed in the
current version.
- Tried to tighten up the algorithm so it would be more in keeping
with other published algorithms, however I found it difficult to omit
any details of the algorithm and still maintain its ideas, when the absence
of some had led to reviewer criticism.
Week 9 (July 29-August 2)
- Project Complete!
Finally, after 5 weeks of programming, I believe my project is complete.
I was finally able to finish cycle detection and correction, and
successfully complete a number of test cases. For the cycle cases, I
tested the program using both major files (files that are loaded into
the top frame in their respective web sites, before they were integrated
to form the cycle examples). Further testing will include a test run of
a real e-commerce frame site and the original shopping cart example.
- Cycles Unraveled
Through my research I found that there are three types of cycles, each
of which are detected at a different point in my find_ptr function
during Phase 3. There are small, or local, cycles that occur when a
document is an element of both the parent_doc and child_docs sets for
the same frame. There exists a special cycle case where the principal
cycle document is a child of the top frame node. Lastly, there are
large cycles spanning multiple document-frame node pairs. My
classification of these three different types of cycles resulted from my
headache the week before over solving my cycle dilemma.
- Submission for Reprobation
Although the initial article describing the work I was studying this
summer was not accepted for publication, the reviewers provided helpful
comments to improve the article's chances for future publication. After
completing most of the project, I was able to view these comments. The
reviewers' ideas were very reassuring and confirmed some objections I
had had when initially approaching the problem. I was encouraged to
discover that I had already rectified some of their complaints:
- Resolving links without explicitly defined targets.
- Fixing the unnamed document node in Figure 1 that does not in fact
exist.
- Rewriting the incorrect code of the frameset tags in Figure 1.
In addition, I found that one of the reviewers had also been troubled
by the idea of name resolution when there exist more than one frame with
the same name within the same level, but with different parent
documents. However, only one such frame may exist at a given time,
since only one of those parent documents will be loaded into the browser
at any particular moment in time.
- Target Lists and Affectable Frames: Phase 3 Explained
My most significant contributions to Part I can be found in Phase 3. I
felt it would be expedient to provide people already familiar with the
project a summary of the changes I made to Phase 3 and the ideas that
triggered these modifications.
- Target Lists
While going through my contrived frame example, I discovered that it may be
difficult to discover what the current loading frame of a document is. This
is an issue when URLs don't contain target
frames. In such cases the URL is loaded into the current frame,
however, the disconnected sub trees of a budding FDT may not yet contain
the information necessary to discover the current frame that a document
is loaded into. The obscurity of the loading frame is due to the fact
that the FDT sub trees are headed by document nodes, not frame nodes.
Having the basic building block of all the sub trees be document nodes is a
necessity, but the issue of finding the current load frame can be
remedied. I have added a TargetList to the FDT algorithm to suit this
purpose. For a given document node d, the TargetList contains a list of
pages, each page containing a URL pointing to d without a target frame
but where the current frame was not known during phase 2 and the
subsequent grafting of the sub trees using the LeafLists. The lack of a
load edge here or there does not greatly affect the FDT, and the
resolution of the target lists is suitable and necessary immediately
following phase 2. For a given element of the TargetList, the current
frame node of the element in question is resolved. A load edge is then
drawn from the current frame node to d (the node whose TargetList is
currently being evaluated).
- Affectable Frames
Affectable frames are used to resolve elements on the dupes list (frames
that are distinct but have the same name). The algorithm works as
follows:
- For a given document node, traverse the tree from path to root,
marking each node along the way.
- For each document on the path to root, explore the sub frames,
marking each frame node. Do not explore any document sub trees of
documents who are children of a frame node on the path to root.
- Return the list of marked frame nodes; these are the affectable
frames for a given document node.
- PTRs
A consequence of finding the affectable frames is finding the Path to
Root (PTR) for each document node. The find_ptr function also detects
and deletes cycles, therefore it is run on all document nodes, not
just the R list (the list of unresolvable links whose targets point
to a frame page that is a duplicate). However, the affectable_frames
function is only run on the R list.
- Part II: Trials and Tribulations
The details of Part II of the paper were a rough sketch of a model that
included HTML and JavaScript. However, most web applications
incorporate technologies to access back-end components, such as
databases, and even intermediate layers of business logic units. Some
web technologies currently in use to achieve such large-scale systems
include: CGI Scripts, JSP, ASP, PHP, and XML. To make our model more
accurate and applicable, I feel we should include at least JSP into the
model. As the research progresses, perhaps we will be able to
incorporate additional technologies.
The difficulty in modeling web applications stems from their dynamic
nature. Web applications typically pull from a variety of sources to
create their dynamic content, and the path the data takes between a
client browser request and the returned page may be long and complex.
In many cases there is no index.html file to analyze, but a
collection of scripts, together with the server and other back-end
components, that creates on the fly the page a client browser sees.
Part of the difficulty in modeling a new technology is finding sample
applications to work with. Perhaps realizing this, Sun has created two
stand alone example applications that can be deployed on a single
machine. These samples make it possible to begin more detailed research
of Part II with client, server, and database components all running from
one local computer.
Week 10 (August 5-August 9)
|

{kind=link}
{kind=link}